跑 Claude Code 改个稍大的项目,一个长任务下来几万 token 就没了。Codex 调试一段日志,光日志本身就把上下文吃掉一大半。更难受的是,这些 token 大部分都是垃圾信息——一百行 grep 结果里真正有用的就那三行,但模型得全读。日志里一大坨是无关的 INFO,可你不敢删,怕漏掉关键报错。
最近刷到一个叫 Headroom 的开源项目,给 AI Agent 装一层上下文压缩层,在所有内容送进 LLM 之前先压一遍。一段 10144 token 的内容,压完只剩 1260。
Headroom 是什么
Headroom 是一个夹在 AI Agent 和 LLM 之间的中间层。你平时喂给模型的所有东西——工具输出、命令行结果、代码搜索结果、RAG 检索片段、文件内容、对话历史——在送进 LLM 之前,Headroom 会先拦下来压一遍。效果基本一样,但是 token 少了一大截。

它有四种接入方式:
- 库(Library):Python 或 TypeScript 里直接 compress(messages) 调用,几行代码接入
- 代理(Proxy):headroom proxy --port 8787 起本地代理,零代码改动,任何 OpenAI 兼容客户端都能套用
- Agent 包装:headroom wrap claude | codex | cursor | aider | copilot,主流编程 Agent 直接包住
- MCP server:注册三个工具 headroom_compress、headroom_retrieve、headroom_stats,MCP 原生客户端直接用

6 种压缩算法
Headroom 不靠一把锤子敲所有钉子。很多同类工具就是简单截断或用一个小模型统一压缩,而 Headroom 会先做内容路由,判断这块东西是 JSON、代码、日志还是自然语言,然后挑对的算法去压。
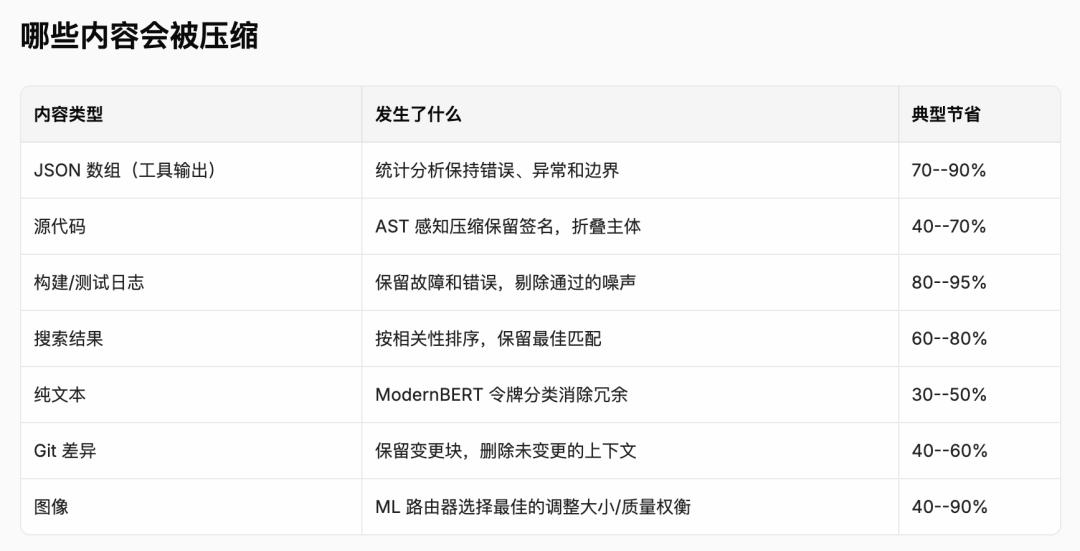
目前内置了 6 种压缩方案:SmartCrusher 针对 JSON 的统计式压缩,节省 70-90%。CodeCompressor 基于语法树进行代码压缩,适用于 Python、JS、Go、Rust、Java、C++,保留 import、函数签名、类型信息,模型读压完的代码还能正确理解结构。
自然语言压缩方面,作者训练了 Kompress-v2-base 模型,用大量 agentic trace 训练,知道 Agent 场景下哪些话可以丢掉。
压了还能找回来
市面上所有压缩方案几乎都有同一个毛病:压完就没了。信息一旦被截掉或被摘要掉,模型万一发现关键信息丢了就没辙。Headroom 搞了个叫 CCR 的机制。
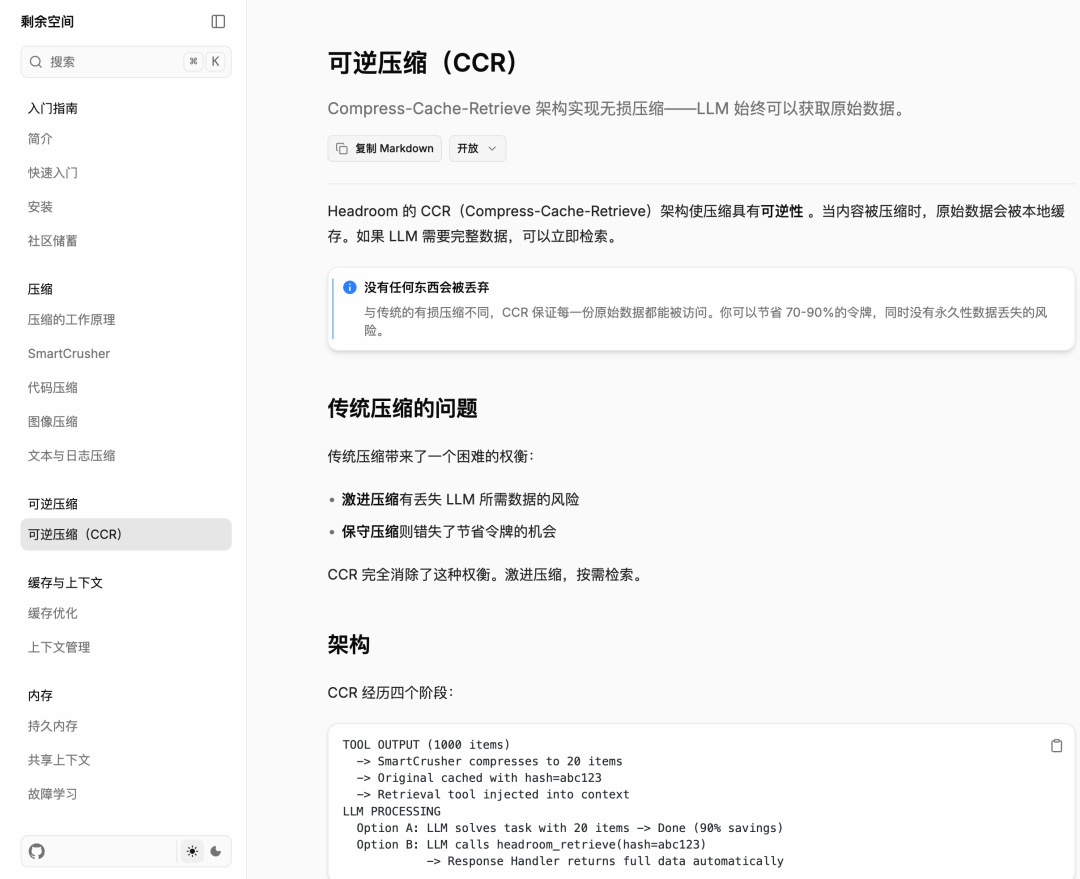
原始数据本地存着,永远不删。压完的精简版送进 LLM,模型如果发现信息不够用,可以直接调 headroom_retrieve 工具把原文按需捞回来。这等于给模型装了个备忘录:日常对话用压缩版省钱,需要细节的时候再翻回原文。

Headroom 覆盖所有容类型(工具、RAG、日志、文件、历史),数据全部留在本地,可逆。在覆盖范围、部署方式、本地化、可逆性四个维度上,Headroom 是唯一全部支持的。
压缩效果和准确性
代码搜索和 SRE 排查这种大量结构化噪声场景效果最猛,token 直接砍掉 9 成。代码库探索因为代码本身信息密度高,压缩空间小,但也有近一半节省。数学题零掉分,事实问答反而涨了 3 个点(可能是压缩后模型注意力更集中),工具调用保持 97%。
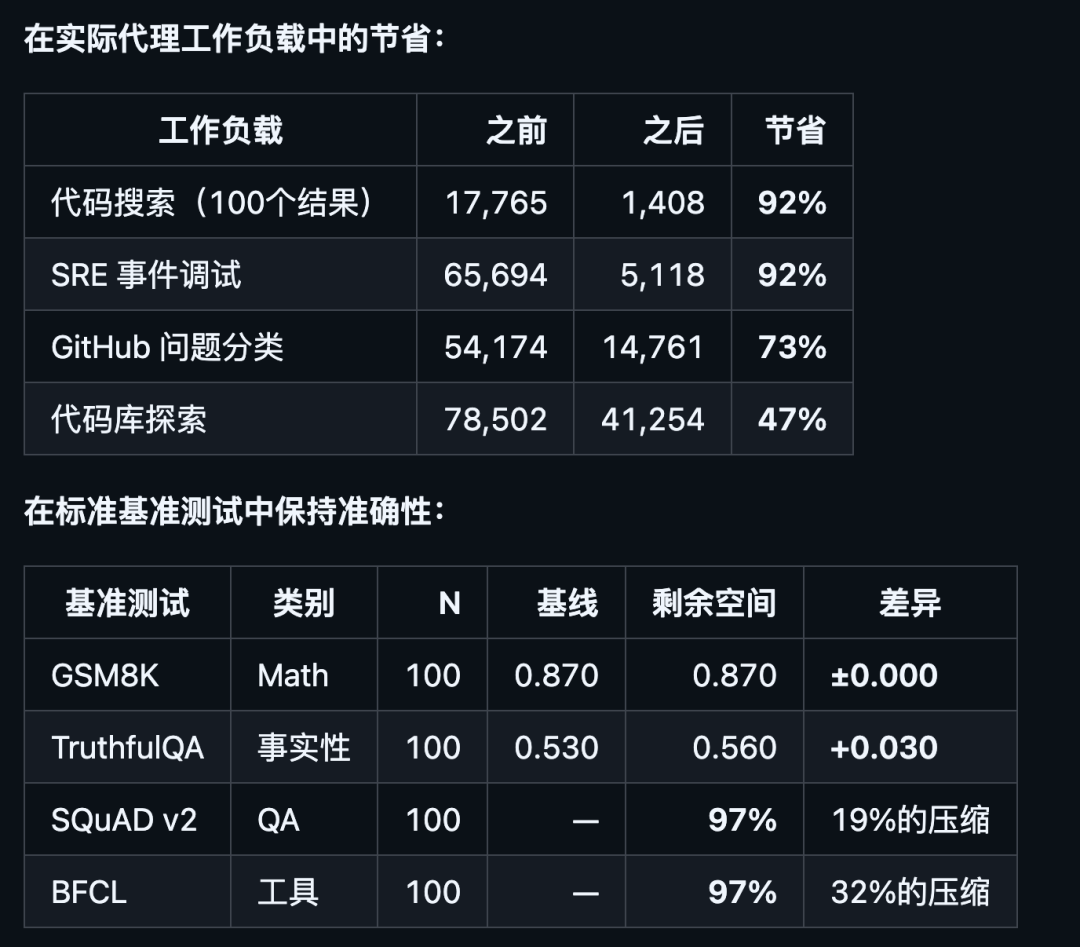
省 token 不以牺牲答案质量为代价。
跨 Agent 记忆和自动学教训
除了压缩,Headroom 还有两个特别实用的功能。
跨 Agent 共享记忆:现在大家手上不止一个 Agent,Claude Code、Codex 等等,如果每个 Agent 各自学一遍项目背景,token 重复消耗。Headroom 搞了个本地 SQLite 加向量库的记忆层,Claude 和 Codex 之间共享同一份记忆,自动去重。Claude 学过的项目结构,Codex 直接拿来用,不用再读一遍。
headroom learn:让 Agent 自己总结教训。这个功能会扫描你跑失败的会话,分析哪里翻车了、为什么翻车,然后自动把约束调整规则写进 CLAUDE.md 或者 AGENTS.md。等于 Agent 在帮你维护规则文件,越用越聪明。

快速上手
上手非常简单,三步:
# 1. 安装
pip install "headroom-ai[all]" # Python
npm install headroom-ai # Node / TypeScript
# 2. 选一种接法
headroom wrap claude # 直接包住 Claude Code
headroom proxy --port 8787 # 起本地代理
# 3. 看省了多少
headroom perf要求 Python 3.10+。如果不想本地装,还有 Docker 镜像:
docker pull ghcr.io/chopratejas/headroom:latest在 token 还是 AI Coding 主要成本和瓶颈的当下,上下文压缩这件事很重要
Headroom 把它做成了一个本地、可逆、覆盖全内容类型的完整方案,接法灵活
加上跨 Agent 记忆和自动学教训这两个加分项,特别适合 AI Coding Agent 深度用户