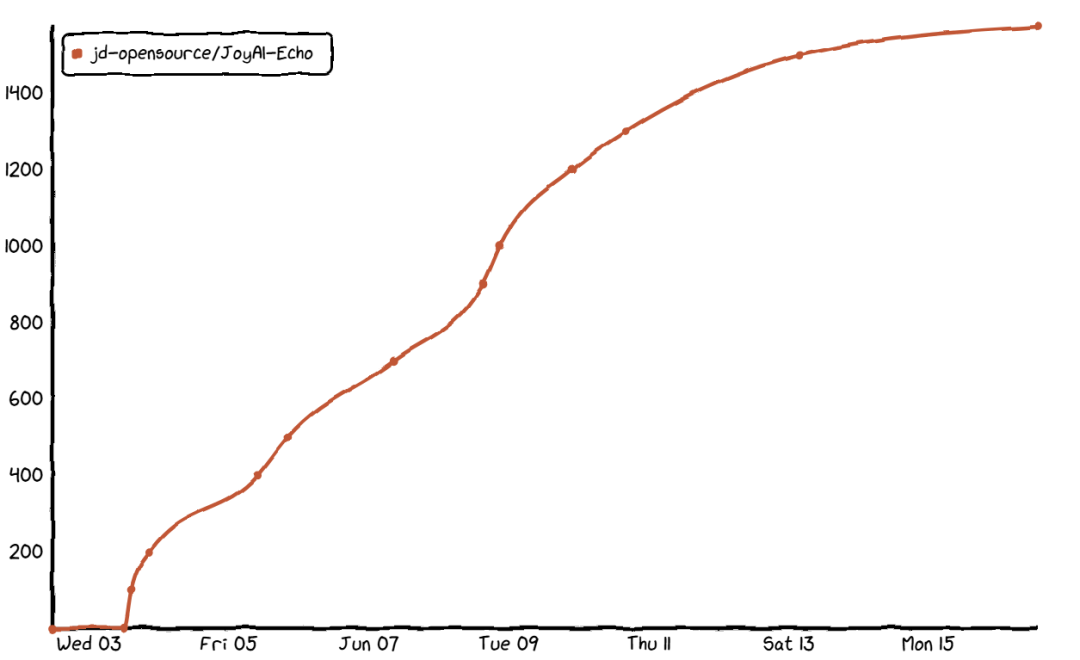
Sora 关闭之后,AI 视频赛道竞争愈发激烈。国产方面,可灵、即梦、海艺都在发力,但长视频角色一致性仍是行业公认难题。最近京东开源了 JoyAI-Echo,在 GitHub 上短短两周获得 1600+ Star。
JoyAI-Echo 是什么
JoyAI-Echo 是京东 JoyFutureAcademy 团队开发的长音频和视频生成框架。它的核心能力是:在几分钟的视频中,即使切换多个镜头,人物的脸部、声音和服饰都能保持一致,不会出现越拍越不像的情况。

6 大核心技术
1. 跨模态记忆库
解决「角色老变脸」的问题。AI 每次生成新镜头时通常没有记忆,不知道上一个镜头里主人公的样子。JoyAI-Echo 给 AI 配上了「记忆库」,当角色第一次出现时记录脸型、声音和穿着等特征,生成后续镜头时从记忆库提取信息作为条件。
该记忆库将视觉与听觉结合,不仅保存人脸照片,还保存声音。生成新镜头时,脸和声音都是同一个人。

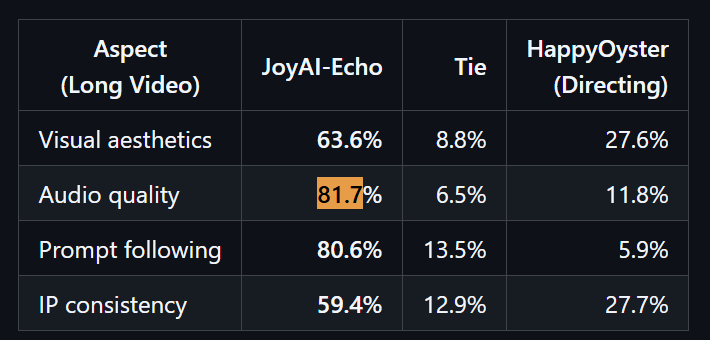
官方测评数据显示,语音内容正确率为 0.8646,用户喜好测试中音频质量达 81.7%,优于其他产品。
2. DMD 分布匹配蒸馏
解决长视频生成太慢的问题。传统多步扩散模型生成几秒到几十秒视频耗时很长,角色一致性越高计算量越大、速度越慢。JoyAI-Echo 使用 DMD 分布匹配蒸馏技术将多步扩散压缩为少步推理,实现约 7.5 倍速度提升,且不降低角色一致性。
3. 音视频联合生成
解决「声音乱变」的问题。传统方式是先制作视频再用外部工具配音,口型和台词难以对上。JoyAI-Echo 一个管道同时输出视频和声音,对白、环境音和背景音乐一起产生,口型与台词同步生成,无需后期人工修改。
音频参数:采样率 16000Hz、梅尔频谱 bins 为 128、窗函数长度 96,保证音质和画面同步。

4. 对话式编辑
解决修改成本高的问题。JoyAI-Echo 提供 Director Agent(导演助理)功能,可以说「把第三个镜头里的主人公换上红色的衣服」,它只会修改这个镜头,无需从头重新制作整个视频。该功能目前处于未发布阶段。
5. 显存优化方案
解决硬件门槛高的问题。JoyAI-Echo 默认配置需要 46-50GB 显存,官方建议使用 H100 或 A100。降级方案:将默认 241 帧改为 121 帧,显存占用大幅减少。项目提供 ComfyUI 集成方案(ComfyUI_JoyAI_Echo 节点包),支持在 48GB 显存下热切换,每个镜头可添加注释并实时预览。
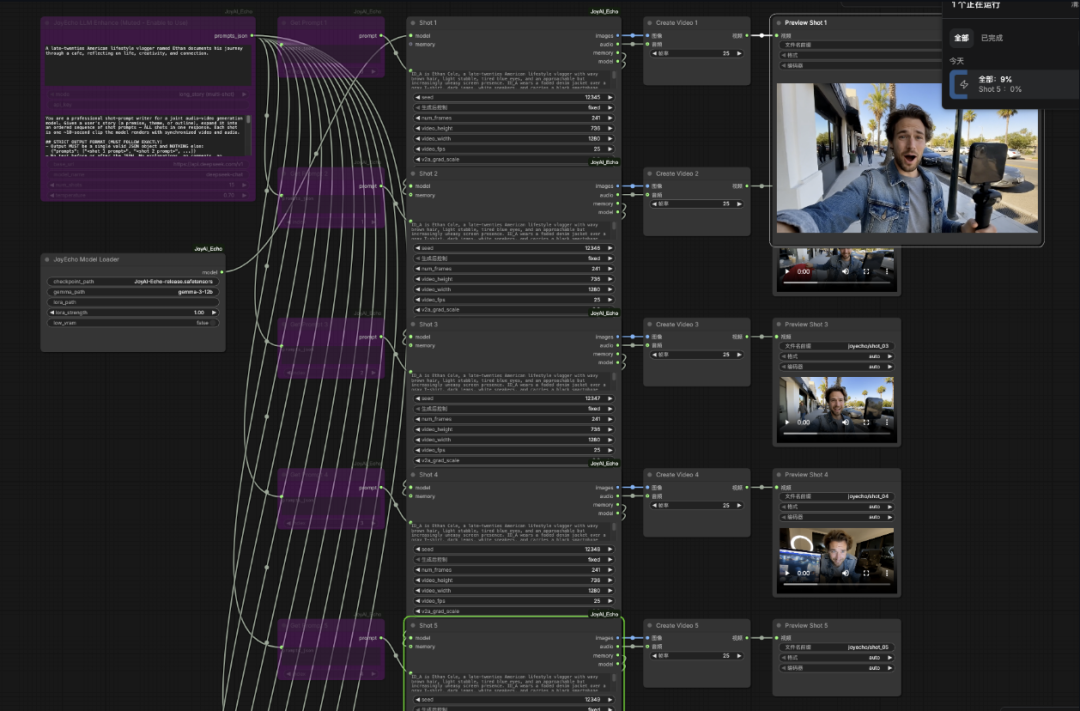
安装使用
最简单的尝试方式是克隆仓库:
git clone https://github.com/jd-opensource/JoyAI-Echo.git
conda env create -f environment.yml
conda activate echo-long下载权重是最大门槛:需要从 HuggingFace 下载约 46GB 模型文件,还有 gemma-3-12b 文本编码器约 24GB。
在 prompts 目录下创建 JSON 格式提示文件,使用 python inference.py 生成视频。项目提供 Prompt Enhancer 功能,可将简短故事想法变成有组织的镜头描写,包含角色、动作、风格、镜头、背景、音效等。
当前限制
- 不支持 I2V(图像到视频),只能由文字生成,不可使用图片作为起始帧
- LTX-2 Community License 仅用于学术研究及非商业目的,商业用途需联系 Lightricks
- 目前只开放推理代码及权重,未开放训练代码
- Director Agent 和 Echo-SR 超分模块标注为待发布
总结
JoyAI-Echo 支持本地部署,视频素材不用上传云端,所有数据本地处理,隐私性更高。对于经常制作长视频、在意人物一致性的用户来说比较有优势。
苏米注:JoyAI-Echo 的跨模态记忆库和音视频联合生成是解决长视频一致性问题的有效思路。虽然硬件门槛不低(46-50GB 显存),但对于有相关配置的用户来说值得尝试。