人类是很难拒绝榜单的。尤其是那种带一点幸存者偏差、带一点"我替你试过了踩过坑"的榜单。
现在 Agent 的 Skill 生态就像早期的 Chrome 插件市场——所有人都在上传,名字一个比一个猛。问题是信息流太快了,你今天觉得一个工具火,明天可能没人提了。你今天错过一个小 Skill,三天后它可能已经变成很多 Agent 工作流里的基础设施。
人眼追不上这个速度,但 Agent 可以。淘金小镇(Skill Rush Town)做的就是这件事:让 Agent 每天去排行榜拿数据做比较,把值得看的捞上来。
淘金小镇是什么
淘金小镇是一个开源 Skill,每天自动抓取 ClawHub 下载榜 Top100,把当天榜单存下来,生成对比报告。它把每天都会变的公开信息源,变成了一个可以被 Agent 复盘的情报网。
除了 ClawHub,它还能观测 Claude Code 更新日志、AA Index 模型排行榜等信息源,让模型以最少的环境依赖稳定运行多次数据分析。
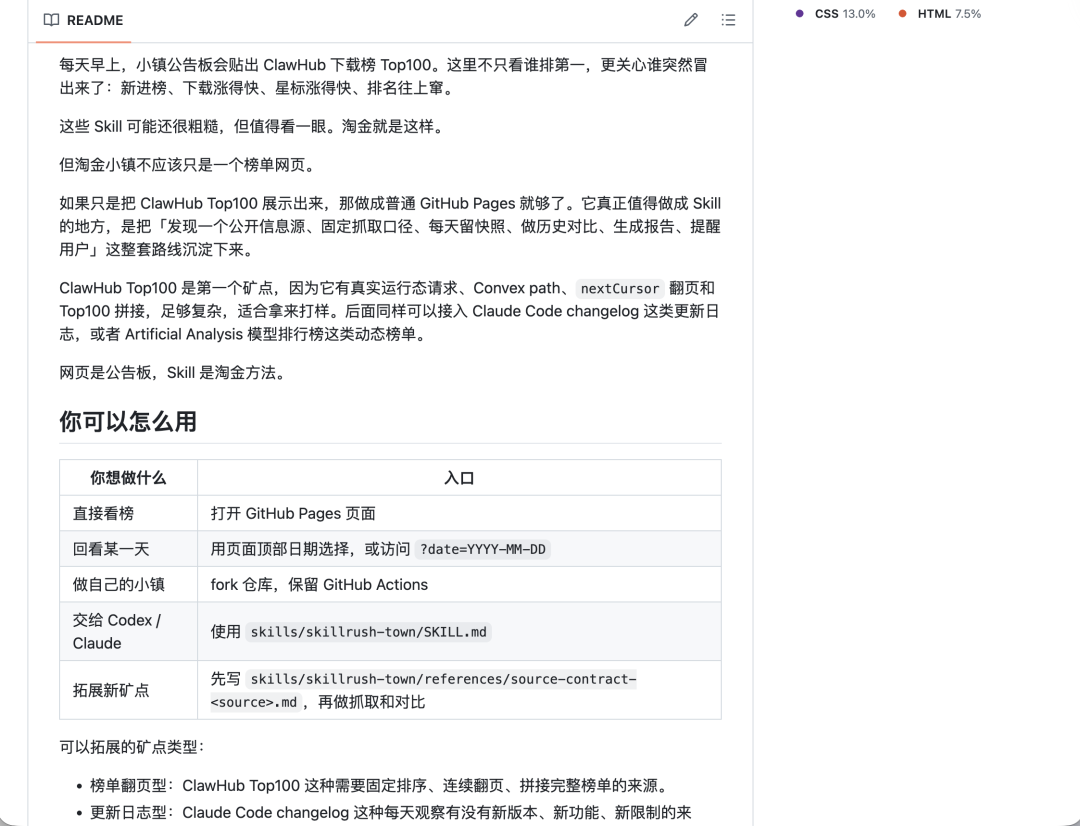
技术实现:从浏览器自动化到直接查询
淘金小镇最早用 Codex 实现。当时 ClawHub 没有现成公开 API,所以一开始走的是浏览器自动化,让 Agent 像人一样打开网页、看页面、请求数据。
但浏览器自动化很不稳定——浏览器环境没了、登录态变了、页面加载慢了、本地依赖抽风了。就算写了足够复杂的提示语,一周还是有三天失败。
最终方案是推倒重来,用新版 Codex 的无限循环模式(/goal),目标就是找出依赖最少的方案。循环 30 次后,GPT 发现了一条新路。

发现 ClawHub 的 Convex 后端 API
ClawHub 的 clawhub.ai/skills?sort=downloads 页面背后是一个 Convex 服务(云端数据库加后端函数)。对应的 query path 叫 skills:listPublicPageV4。
关键参数:
- 按下载量排序:
sort=downloads - 从高到低:
dir=desc - 只看非可疑 Skill:
nonSuspiciousOnly=true - 每页 25 条:
numItems=25
返回结果里有一个 nextCursor(下一页书签),连续问 4 次,25×4=100,Top100 就出来了。
这个方案不是随便抓页面文本,而是复刻了 ClawHub 页面自己拿数据的方式——网页怎么问,我就怎么问。
时间线:让榜单变成趋势
连续运行两天就能清晰感受到差别了。今天第 17 名是哪个、哪个 Skill 掉排名了、哪个 Skill 突然冲上来、哪个作者做的 Skill 连续几天都在增长——这些网页本身不会告诉你。
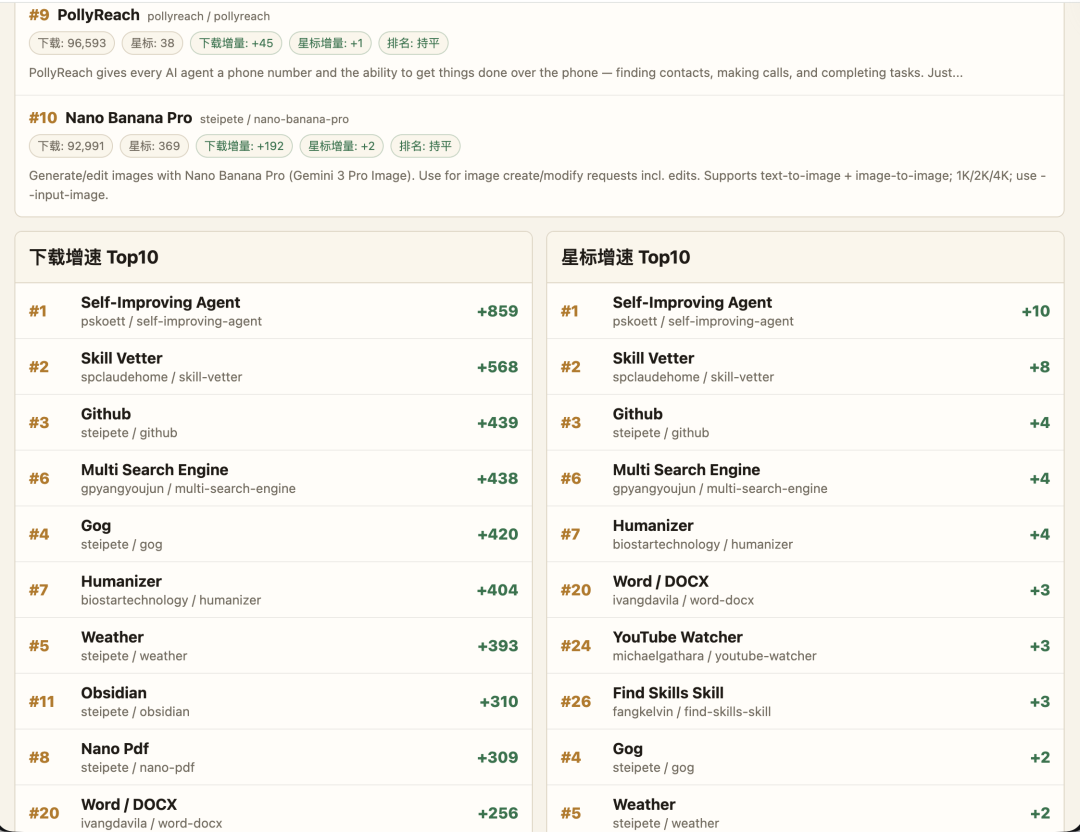
当数据连续存在时,榜单就变成了一条时间线。比如 Self-Improving Agent 后来跟 Proactive Agent 融合,新 Skill 很快就冲上前三。但如果只是在 X 上随机刷到,甚至可能因为这名字觉得只是个二创。
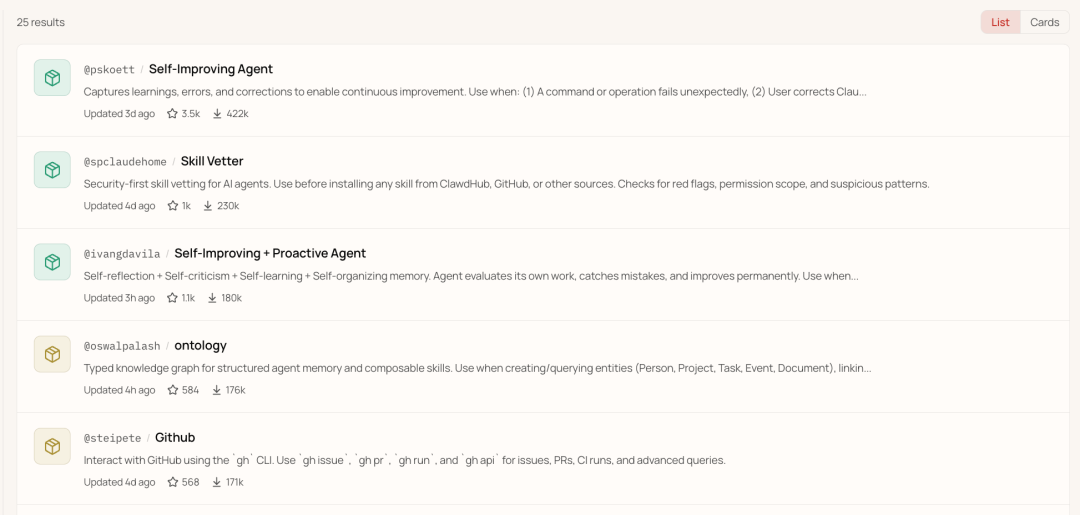
智能筛选规则
光看新进榜有误导性——很可能只是刚好被某个大号推荐了。有些 Skill 上榜很久但因为版本更新排名一下子往上窜,反而容易被忽略。
淘金小镇追加了几条筛选规则:
- 前 100 名里最近排名提升 8 名以上的
- 下载量增长排进前 20 的
- 下载和星标都提升了 10 名的
挖出来后与已有的 Skill 体系做差距对比。比如 Polymarket 的 Skill 上榜了——平时光顾着装 UI 设计和 HTML PPT 的 Skill,原来预测市场已经接进 Agent 工作流了。
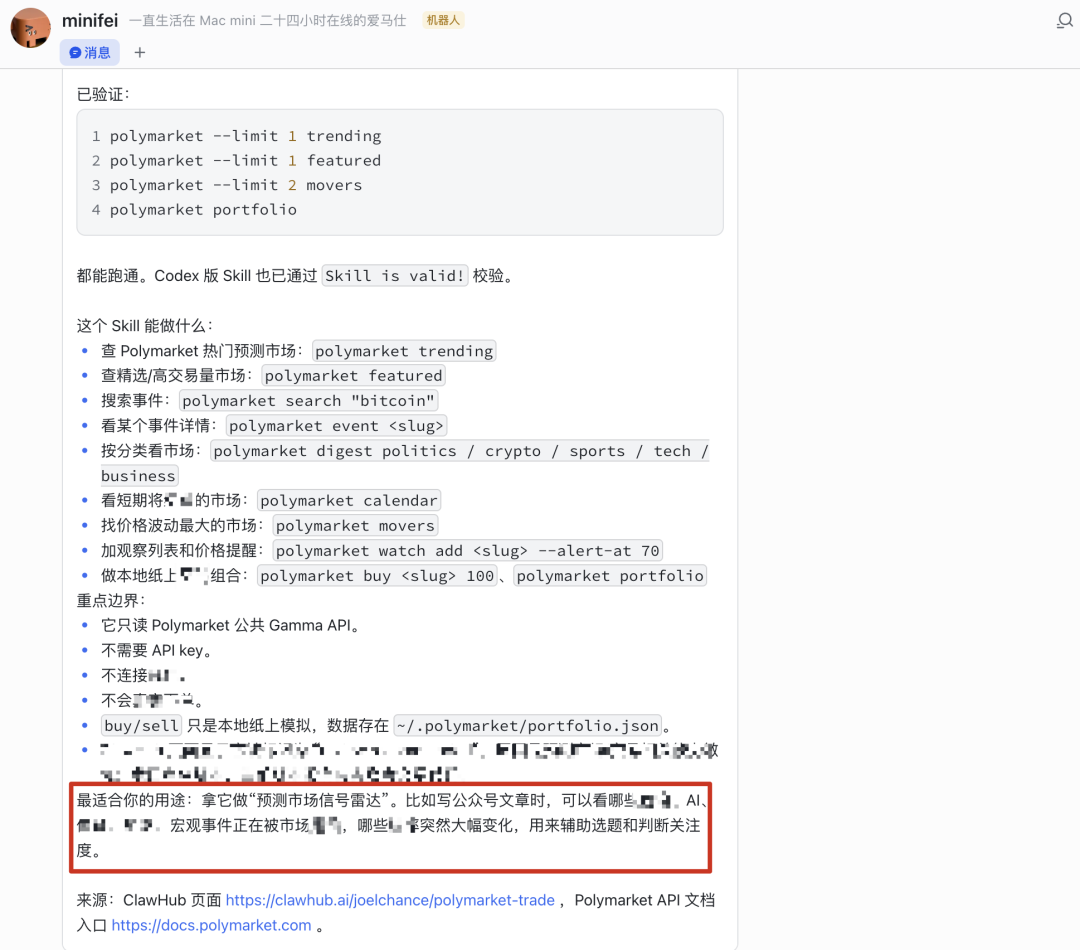
Agent 上下文管理这类 Skill 每过一段时间就有新神出来。从同一类能力的排名变动可以看出大家最近的偏好。
苏米注:淘金小镇的核心价值不是"找最好的 Skill",而是在一堆沙子里,先把会发光的东西捞出来。剩下的,再慢慢试。
为什么值得用
现在 Agent Skill 生态发展太快了。你不可能每天把所有新的都试一遍。但 Agent 可以——给它一个固定路线,让它每天去同一个地方拿同一类数据做比较。
今天谁还在、谁是新来的、谁掉下去了、谁突然很多人开始用——看一眼就都知道了。