摘要:本文详解如何使用 Obsidian 搭建本地 AI 知识库,基于 Andrej Karpathy 开源的 LLM Wiki 方法。通过三层文件结构(原始资源层、维基文件层、模式与规则层)和 AI Agent 配合,实现知识的原子化提炼、双向链接和持续累积。
前段时间,Andrej Karpathy 开源了他的本地知识库管理方法 LLM Wiki,仅靠一个文档就获得了 GitHub 5k star。
Andrej Karpathy(安德烈・卡帕西)是当今全球最具影响力的深度学习、计算机视觉与大模型专家之一。他是 OpenAI 最早的核心成员之一,后来去了特斯拉负责自动驾驶 AI,一手打造了特斯拉"纯摄像头方案"。
在他的方法中,核心是使用 Obsidian + LLM 大模型构建知识库。
为什么选择 Obsidian?
Obsidian 是一款本地笔记工具,记录的文件类型是 Markdown 格式。
在 AI 时代,Obsidian 凭借独特的架构成为了极具优势的个人知识库工具,其核心特征可以归结为以下 3 点:
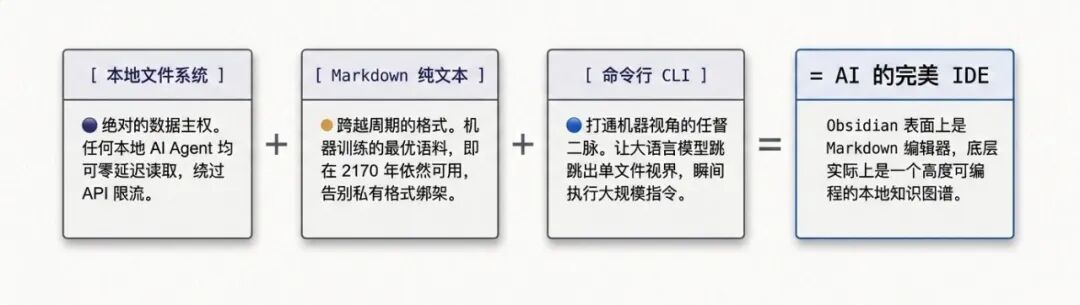
1. 数据主权完全归用户
你的笔记全部以纯文本 Markdown (.md) 格式保存在本地设备上,而不是被锁在云端服务器或封闭的私有格式中。
2. 强大的网状知识结构
传统的笔记软件多采用树状文件夹结构,而 Obsidian 的核心是双向链接功能。如果你的笔记之间存在关联,它会自动建立起错综复杂的网状知识拓扑结构。
3. 与 AI 的天生契合
由于笔记存放在本地且格式是 AI 最熟悉的 Markdown,本地的 AI 可以直接、瞬间地读取、分析和修改这些文件。再配合 Obsidian CLI(命令行接口),AI 甚至能直接看懂整个知识库中的网状链接关系。
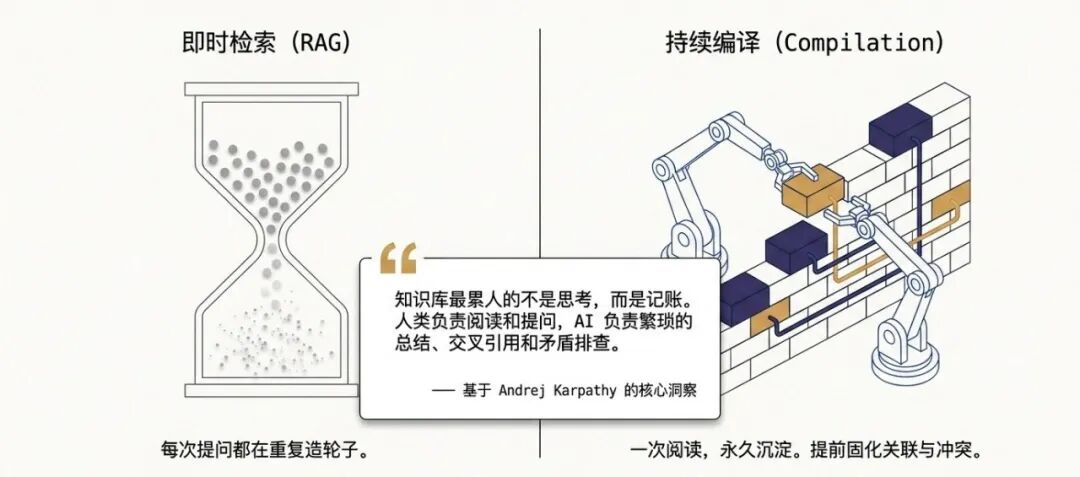
LLM Wiki vs 传统 RAG
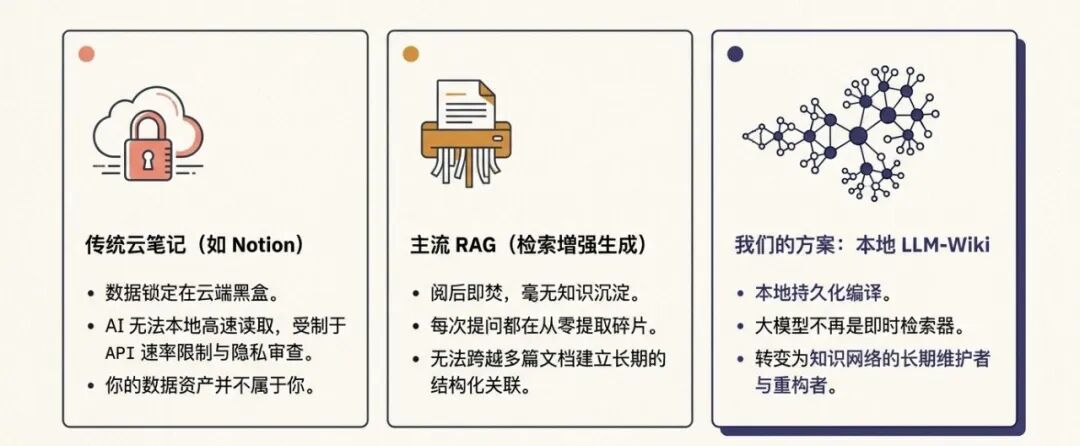
传统知识库用 RAG 模式,每次提问 AI 都在重头找片段拼凑。而 LLM Wiki 模式主张让 AI 承担将新知识提炼并"编译"成结构化、带双向链接的维基图谱,实现知识的真正复利与累积。
搭建 AI 本地知识库:完整步骤
步骤一:创建知识库文件夹
下载 Obsidian,然后在桌面创建一个 AI 知识库的文件夹(名字随意,例如 Knowledge),用 Obsidian 打开这个文件夹。

步骤二:配置 AI Agent
使用支持本地文件操作的 AI Agent(如 WorkBuddy、QClaw、CodeBuddy、Claude Code、Codex 等),选择同一个文件夹。
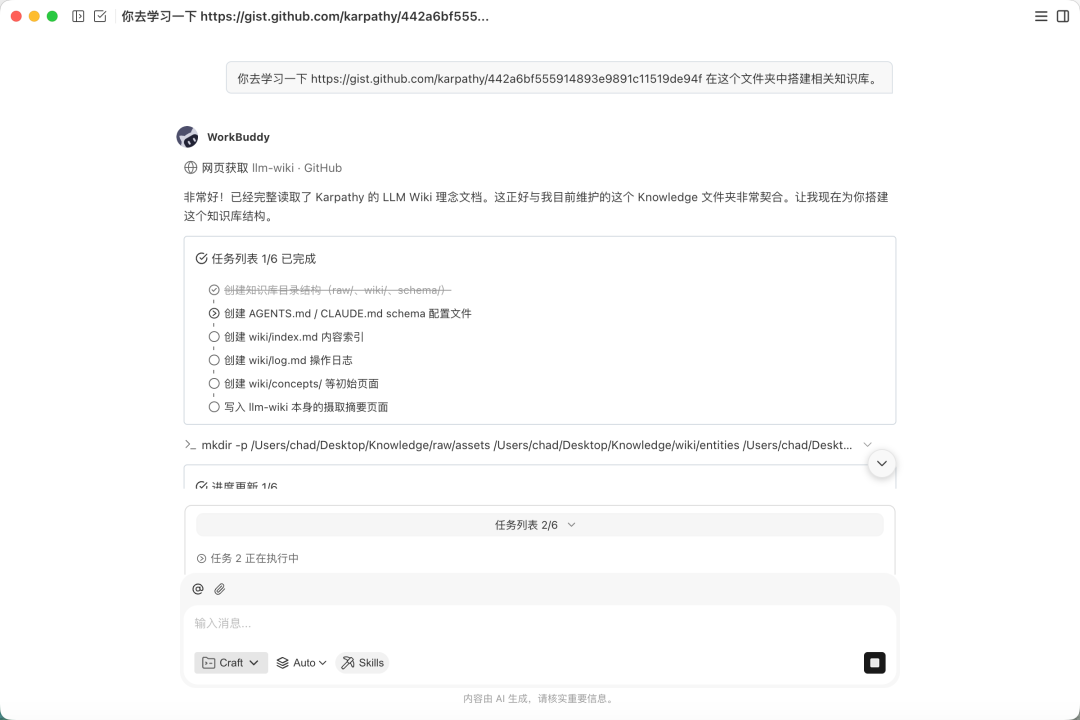
步骤三:让 AI 学习并搭建结构
直接告诉 AI:
你去学习一下 https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
在这个文件夹中搭建相关知识库。AI 会自动学习教程内容,并根据学习结果创建文件夹与相关文件。
知识库核心逻辑:三层文件结构
根据 Karpathy 的理念,一个成熟的 LLM Wiki 系统由三个核心数据层和两个辅助文件构成。
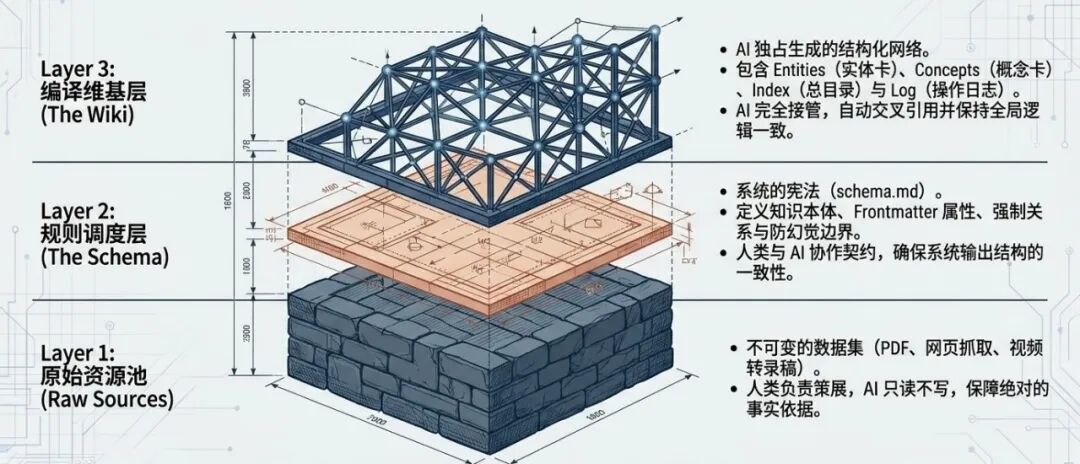
三层文件结构
| 层级 | 用途 | 原则 |
|---|---|---|
| 原始资源层 (Raw sources) | 存放外部 PDF、网页剪藏、播客转录稿等 | 只读不改 |
| 维基文件层 (The wiki) | AI 提取生成的结构化 Markdown 文件,含双向链接 | 核心层 |
| 模式与规则层 (The schema) | CLAUDE.md 等配置文件,约定目录结构、标签规范 | 大脑配置 |
两个辅助文件
索引表 (index.md):维基的花名册。AI 每次创建新页面都必须在这里追加一行,写明"页面链接 + 一句话摘要"。AI 回答问题时只需先扫一眼 index.md,就能精准定位需要深度阅读的笔记。
日志库 (log.md):AI 的时间线记忆。按时间顺序追加记录,例如"2026-04-14,摄取了文件 A,创建了概念 B,添加了链接 C"。
AI 搭建完成后的目录结构如下:
Knowledge/
├── CLAUDE.md ← Schema 配置(知识库的"大脑")
├── raw/
│ ├── assets/ ← 图片附件存放处
│ └── llm-wiki-karpathy.md ← Karpathy 原文归档
└── wiki/
├── index.md ← 所有页面的内容导航
├── log.md ← append-only 操作日志
├── concepts/ ← 概念页面
│ ├── llm-wiki-pattern.md
│ ├── rag-vs-llm-wiki.md
│ └── ...
├── entities/ ← 实体页面
│ ├── andrej-karpathy.md
│ ├── obsidian.md
│ └── ...
├── sources/ ← 来源摘要
└── syntheses/ ← 综合分析
在 wiki 目录中,AI 会给内容打上标签、取标题、做内容提炼和双链。
可视化知识图谱
Obsidian 可以切换成关系图谱模式,可视化笔记之间的关系,通过直观的交互式图谱发现思维中隐藏的模式。
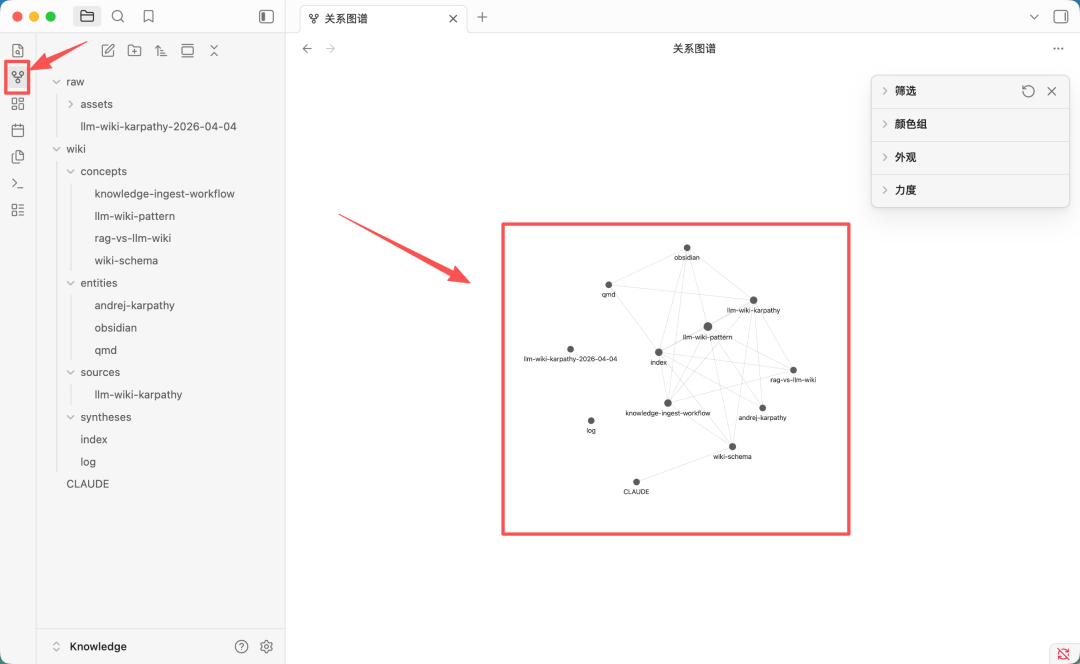
每个知识点可以拖拽查看相关联的知识,点击即可查看具体内容。
知识库管理:三个核心操作
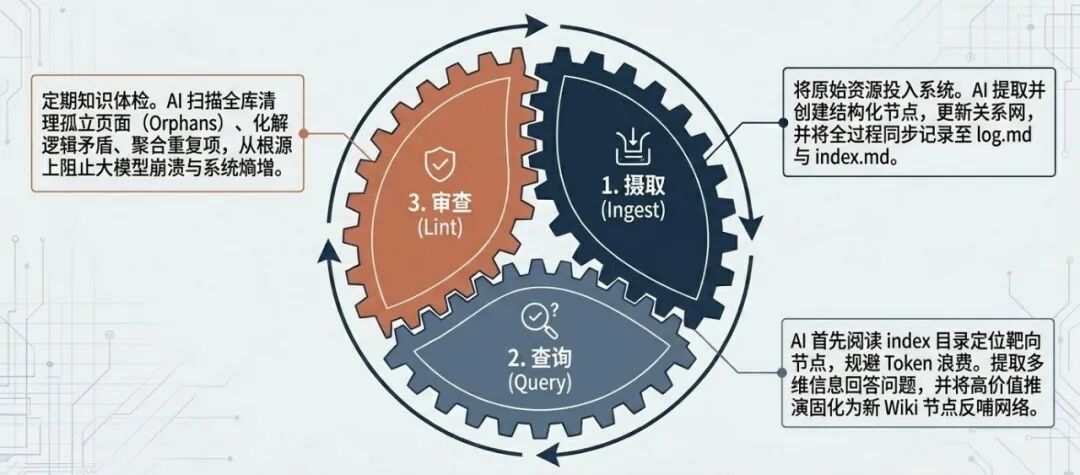
操作一:摄取 (Ingest) - 知识的原子化提炼
当你读到一篇好文章,直接把链接发给 AI:
帮我把这篇文章 https://mp.weixin.qq.com/s/xxx
整理成 md 格式放入 raw 文件夹,
然后根据 Schema 规范,提炼这份新资料。AI 会先处理文章,将其隔离处理成 md 格式,然后仔细阅读原文,将其拆解为多个独立的知识点。它会检查这个概念是否已存在于 Wiki 中,如果不存在就新建页面,如果存在就把新观点补充进去。
随后,AI 会在相关页面之间打上双向链接(如用 [[概念 A]] 链接到 [[概念 B]]),最后自觉地去更新 index.md 和 log.md。
苏米注:这个流程的关键在于"原子化"——每个知识点独立成页,通过双向链接形成网络。这样 AI 可以在瞬间关联 15 个甚至更多文件,远超人类的记忆能力。
操作二:问答 (Query) - 知识的涌现与固化
当你在思考某个新问题时,直接向 AI 提问:
基于我的 wiki 知识库,
我最近创业遇到了推广问题,
推荐一个能帮助我的 skillAI 会翻阅内部的 Wiki,综合多篇卡片笔记为你生成带引用的答案,极大提高了准确率。
如果回答不错,可以直接说:
非常好,请把它固化为一篇新的 wiki 笔记保存下来。通过这种方式,你的灵感被永久沉淀,知识库在日常问答中实现了二次生长。
操作三:审查 (Lint) - AI 驱动的知识库体检
传统笔记的弊端在于"记完就吃灰",内部充满死链接和矛盾信息。现在可以定期(如每周一次)对 AI 说:
对我的知识库进行 Lint 审查。AI 会自动扫描全库,找出没有关联任何页面的"孤立页面(Orphan pages)",梳理出相互矛盾的知识点,甚至建议将两个高度相似的概念页面进行合并。
移动端接入:微信 + 本地知识库
结合腾讯版本地"龙虾"(WorkBuddy)可以被微信接入,就可以在手机上轻松阅读信息,让电脑上的 AI 管理知识库。
需要注意:一开始 AI 不知道知识库的存在,手机和电脑的对话不是同一个,所以需要先让它学习:
你先学习下我桌面的本地知识库的规则文件,
然后帮我把这篇文章内容处理下
https://mp.weixin.qq.com/s/xxx
处理过一遍之后再告诉它,让它记住这个操作。
记住以后让你学习,你都需要去操作我的本地知识库使用建议:三点注意事项
苏米注:在正式使用这套 AI 知识库系统之前,一定要注意以下 3 点,这是我实际使用后的经验总结。
1. 别指望 AI 帮你"从零学习"
这套系统更适合你学完之后,用来整理、复习和建立连接,而不是直接拿来入门。
2. 别盲目堆资料
让 AI 一口气生成几百个词条,但你自己不看,其实没啥用。
3. 你才是大脑,AI 只是工具
AI 是加速器,不是替代品。方向、判断、取舍这些事,还是得你来。
AI 可以帮你整理知识,但不能替你思考。