作为一名长期接触AI产品的从业者,我发现PDF文档处理始终是一个高频痛点。
市面上的解决方案要么功能受限,要么依赖云端服务存在数据隐私风险,要么价格不菲。
最近在GitHub上发现的MinerU项目,恰好填补了这个空白——它是一款开源免费的PDF文档解析工具,已累积47.2k+ Star,值得详细了解。
项目定位
MinerU的核心功能是将PDF等文档格式转化为机器可读的结构化格式(Markdown、JSON、LaTeX、HTML等)
主要面向以下场景:
- 大模型语料处理:将文献、教材、报告等转换为LLM训练友好的格式
- RAG系统数据准备:提取结构化知识用于向量化和检索增强
- 本地隐私处理:涉密文件可在本地部署环境中完成解析,无需上传云端
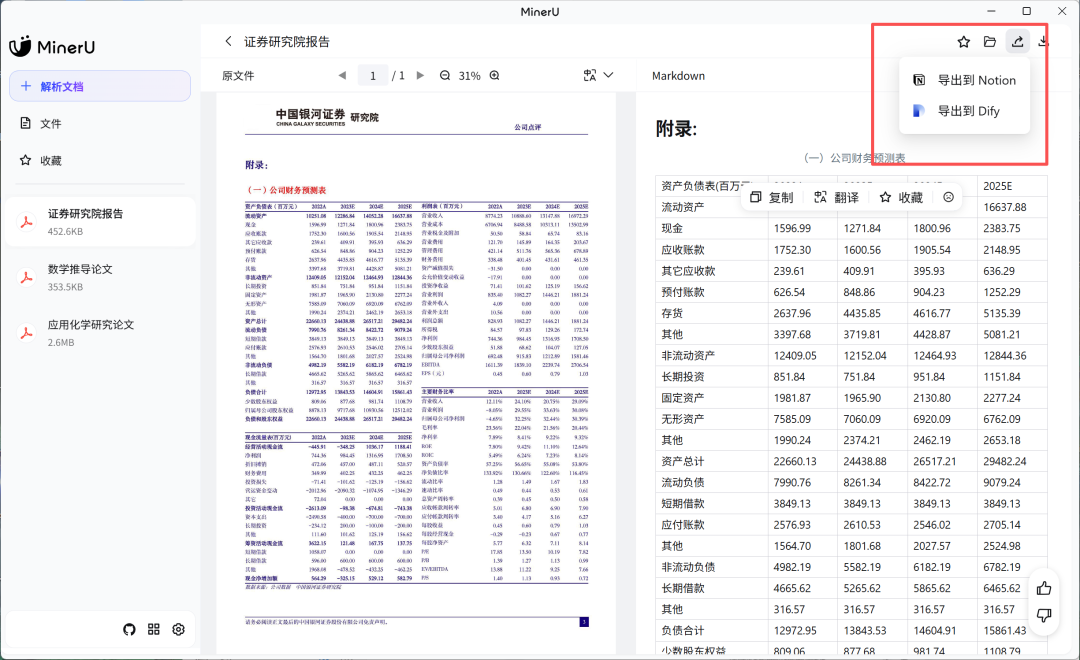
- 工作流集成:原生支持导出至Notion、Dify等协作工具
核心功能
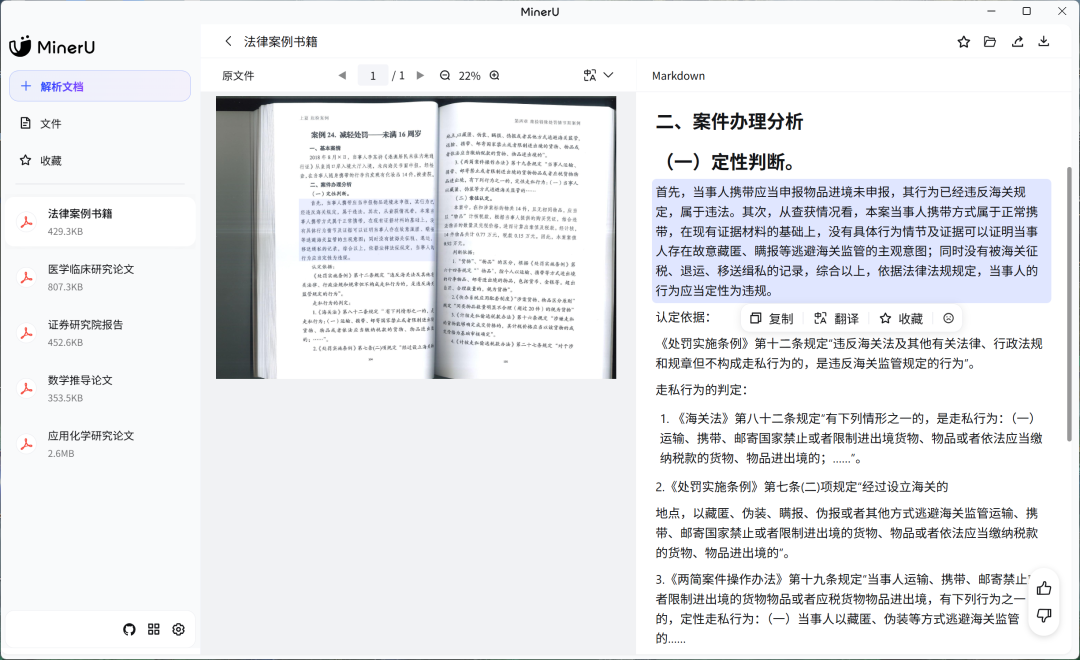
一、核心功能

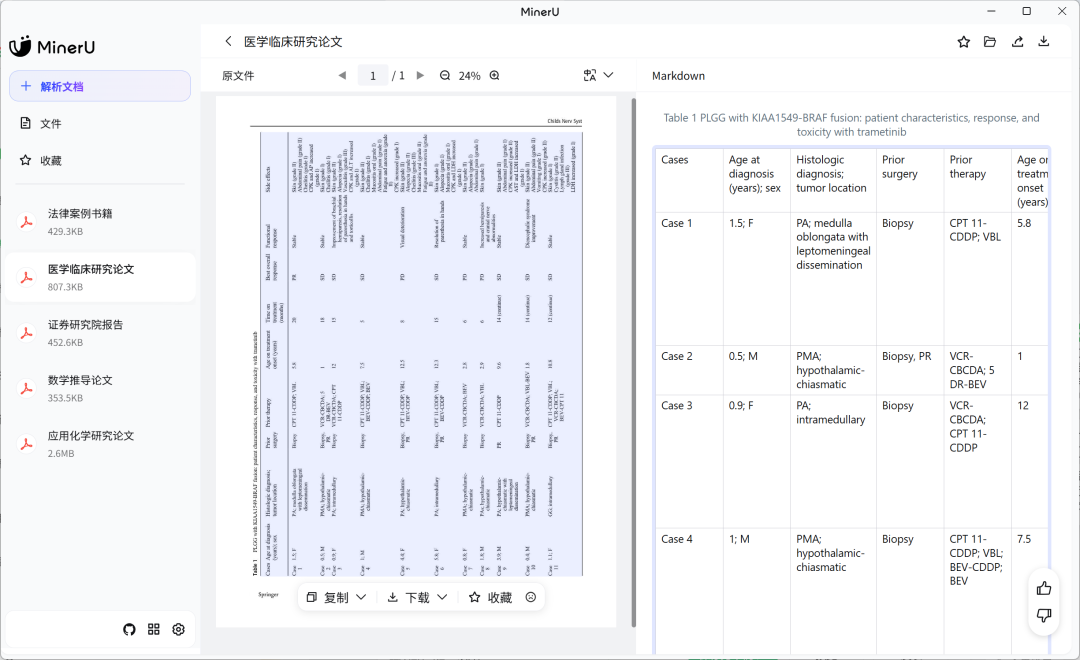
二、支持复杂元素无损提取
-
完美解析旋转、跨页、合并单元格表格 -
高保真导出CSV/HTML/Markdown等格式
-
支持长公式、多行公式、复杂公式的精准识别 -
输出LaTeX/MathML格式确保可编辑与复用

-
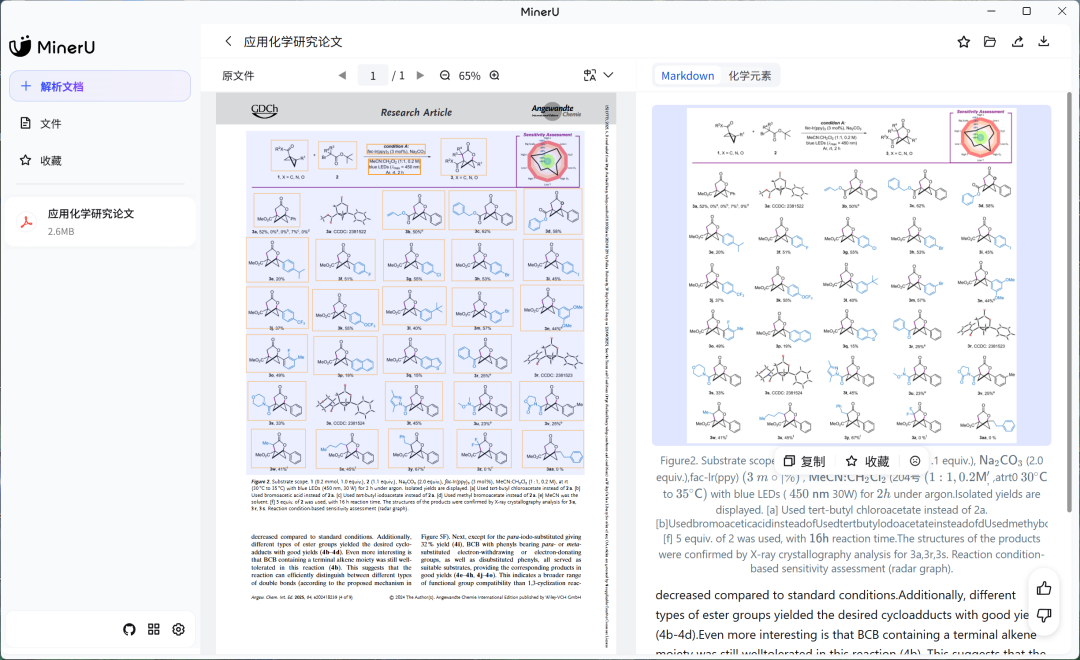
精确的分子检测 -
SOTA 性能的分子结构图识别能力 -
原子和键的识别与原始图像严格对应
-
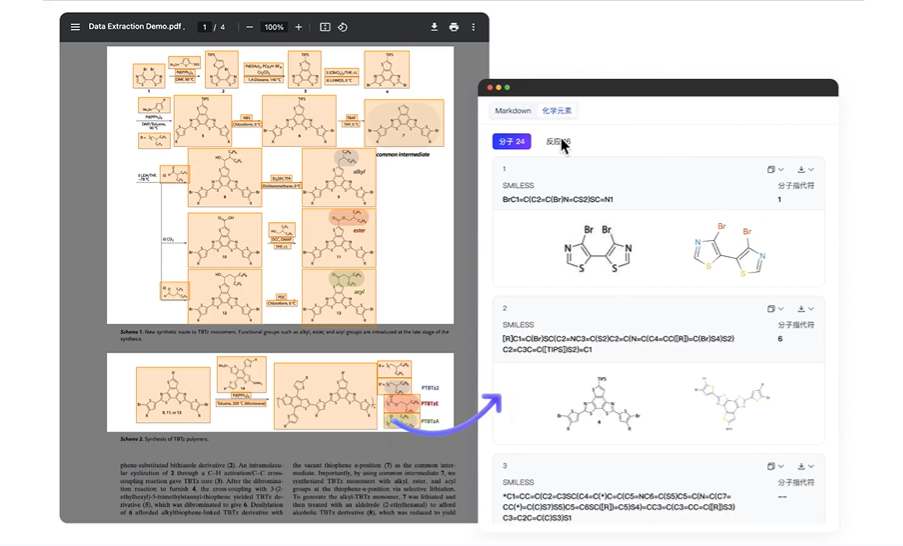
精确提取和解析化学反应过程 -
识别反应物、反应条件等关键要素
-
精确提取图片和文本中的分子标识符 -
SOTA 实现全局分子关联 -
获得分子-文本交错数据

部署与使用
MinerU提供多层次的使用方案,适配不同用户需求:
方案对比
| 部署方式 | 适用场景 | 优势 | 限制 |
|---|---|---|---|
| 在线Web版 | 轻量级处理、快速体验 | 无需安装,即开即用 | 文件上传至云端,隐私性较低 |
| 客户端应用 | 日常办公、小规模批处理 | 支持Windows/Mac/Linux | 本地存储与处理能力受限 |
| 本地部署 | 涉密文件、大规模处理、定制集成 | 完全本地化,隐私可控,可集成工作流 | 需要一定的技术能力配置 |
快速开始
官方资源:
本地部署通常涉及Python环境配置与依赖安装,具体步骤可参考GitHub文档。对于有隐私要求的团队,本地部署方案值得投入。
应用场景
学术与科研:快速批量处理论文、教材、报告,加速知识结构化
企业知识库建设:将历史文档转为RAG系统的语料库
AI模型训练:为LLM微调与预训练提供清洁的结构化数据
自动化工作流:与Dify、Notion等工具打通,实现端到端自动化
相似项目
如果你正在评估PDF处理方案,还可以关注:
- Marker:轻量级Markdown转换工具,功能范围较窄但部署简单
- Pydantic PDF:侧重结构化数据提取,适合特定业务场景
- LlamaParse:云端服务方案,精度较高但有隐私顾虑
相比之下,MinerU的优势在于本地化部署 + 复杂元素处理的广度 + 开源免费的成本结构。
总体评价
从产品角度看,MinerU解决了一个长期存在但被忽视的问题:如何在保证数据隐私的前提下,高效处理复杂文档中的结构化内容。
它的核心竞争力不在于单项功能的突破,而在于功能组合的完整性——同时支持表格、公式、分子结构等复杂元素,这在开源方案中相对罕见。对于有批量文档处理需求、关注数据安全、或需要集成工作流的团队而言,这套方案的性价比值得认真评估。
如果你也在为PDF解析方案的选型而困扰,建议先在官网尝试在线版体验,再根据实际场景考虑本地部署。
毕竟,开源 + 免费 + 功能完整,这样的组合确实难得。