最近在GitHub浏览时发现了Skyvern这个项目,它已经累积了近2万的Star。
这让我想起了自己曾经维护过的Selenium脚本——每次网站稍作调整,一堆XPath和CSS选择器就得跟着改,特别痛苦。
Skyvern的核心思路很有趣:与其死守选择器,不如让AI像人类一样"看懂"网页。
这次想从产品经理的角度,深入分析这个项目的设计思路和实际应用价值。
项目定位
Skyvern定位为基于视觉理解的浏览器自动化框架,主要解决传统RPA工具的两个核心痛点:
脆弱性:传统Selenium、Puppeteer等工具依赖CSS选择器或XPath定位元素,页面结构变动后脚本立即失效
维护成本高:每次网站更新都需要人工调整选择器规则,对于大规模自动化任务来说成本巨大
Skyvern的解决方案是引入多模态AI(视觉 + 语言模型),让系统能够基于页面的视觉内容和语义理解来执行操作,而非依赖HTML结构。

技术架构
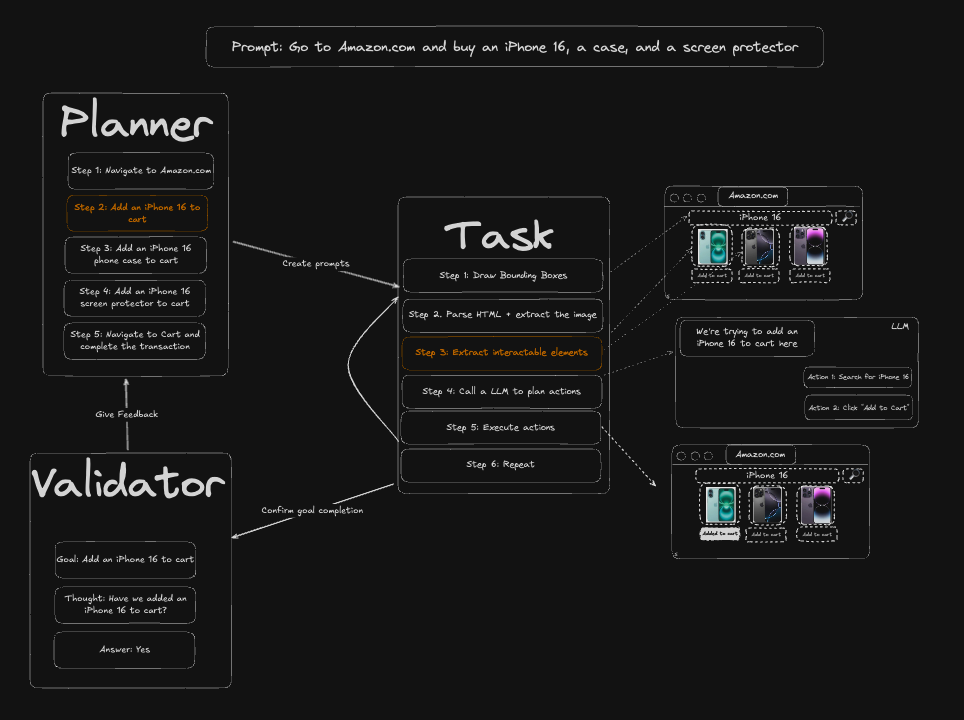
项目采用了典型的规划-执行-反馈三层架构:
| 模块名称 | 职责 | 技术特征 |
| Planner(规划器) | 将用户的自然语言指令拆解为可执行的子步骤序列 | 调用LLM进行任务分解,产生执行计划 |
| Task(执行器) | 逐步执行规划器分配的任务,通过视觉识别和交互完成网页操作 | 结合计算机视觉(OCR、对象检测)和浏览器控制 |
| Validator(验证器) | 确认每一步操作是否真正完成,决定是否继续或重试 | 页面状态对比、内容校验,防止盲目执行 |
举个实际场景:当用户下达"在Amazon上购买iPhone 16、手机壳和屏幕膜"的指令时:
- Planner将其拆解为:登录 → 搜索iPhone 16 → 加入购物车 → 搜索手机壳 → 加入购物车 → 搜索屏幕膜 → 加入购物车 → 结账
- Task模块逐步执行,每一步都通过视觉识别定位按钮和输入框,而不是硬编码的选择器
- Validator在每步完成后验证(如确认商品确实添加到购物车),若失败则触发重试或上报
应用场景
根据架构特性,Skyvern较为适合的场景包括:
- 高频变更的网站操作:如爬取新闻网站、社交媒体热榜等,页面结构经常调整但业务逻辑稳定
- 多步骤跨页面流程:电商购物、表单填写、数据查询等,需要多步骤协调的任务
- 无API接口的系统集成:某些遗留系统或第三方网站只能通过UI交互
- 动态内容处理:JavaScript渲染的动态页面,传统选择器定位困难
实际使用体验
Skyvern提供了两种集成方式:
1. Docker部署(推荐新用户)
提供完整的Web UI界面,可实时观看浏览器自动化的执行过程:
git clone https://github.com/Skyvern-AI/skyvern.git
cd skyvern
./run_skyvern.sh init # 初始化,需配置LLM API Key(OpenAI/Claude等)
docker compose up -d启动后访问 http://localhost:8080 即可使用Web界面提交任务。
2. Python SDK集成
适合已有系统集成需求的开发者:
pip install skyvern
from skyvern import Skyvern
skyvern = Skyvern(api_key="your_key")
task = await skyvern.run_task(
prompt="在Hacker News找到今日热度最高的帖子,返回标题和链接"
)
print(task)实际执行特性
- 执行速度:相比传统RPA工具,Skyvern的执行速度较慢(每个操作需要视觉识别 + LLM调用),不适合高吞吐量场景
- Token消耗:每个任务步骤都涉及截图发送给LLM、文本生成等,API调用成本相对较高,被社区戏称为"Token消耗神器"
- 准确性:受LLM模型能力影响,复杂或非常规UI设计的页面识别准确率可能下降
- 可监控性:UI界面提供实时执行画面查看,便于调试和问题排查
类似项目
市场上也存在其他浏览器自动化方案,做个简单对比:
| 项目 | 技术路线 | 依赖选择器 | 成本 | 适用场景 |
| Selenium | WebDriver协议 | 是(XPath/CSS) | 低 | 需求稳定、页面变动少的场景 |
| Puppeteer | Chrome DevTools Protocol | 是(选择器) | 低 | Node.js环境、API自动化为主 |
| Skyvern | 视觉 + LLM | 否 | 中等(API调用) | 页面变动频繁、复杂多步流程 |
| Browser Use(Anthropic) | 视觉 + Claude | 否 | 中等(API调用) | 通用浏览器任务自动化 |
部署与配置
依赖环境:Docker、Docker Compose(推荐)或Python 3.8+
LLM配置:需配置OpenAI、Claude或其他支持的模型API Key,作为规划和执行决策的核心
资源占用:Docker方式下需要一定的CPU和内存(建议至少2核4GB)用于浏览器实例和LLM推理
网络要求:需要稳定的网络连接以调用外部LLM API和访问目标网站
总结
Skyvern代表了浏览器自动化领域的一个有趣尝试——用AI视觉能力取代脆弱的选择器规则。从产品设计角度,它在易维护性和鲁棒性上相比传统工具有明显优势,尤其对于页面频繁变动的场景。不过需要注意的是,这种方案的代价是执行速度和API成本的增加,所以它更适合对时效性要求不高、对稳定性要求高的任务。
如果你正在处理以下问题:
- 维护大量因网站更新而频繁破损的RPA脚本
- 需要处理动态渲染、结构复杂的现代Web应用
- 对自动化的可靠性比速度更看重
那么Skyvern值得一试。而如果你的场景是高吞吐量数据采集或API完全可用,传统方案仍是更经济的选择。
项目地址:https://github.com/Skyvern-AI/skyvern
体验地址:https://app.skyvern.com/workflows