大家有没有这种感觉: 明明只想让大模型看10段资料,它偏偏要硬塞100段,消耗的token数像火箭一样增长,速度还慢得像乌龟?
恭喜你,这个行业通病,Meta今天直接给治好了。

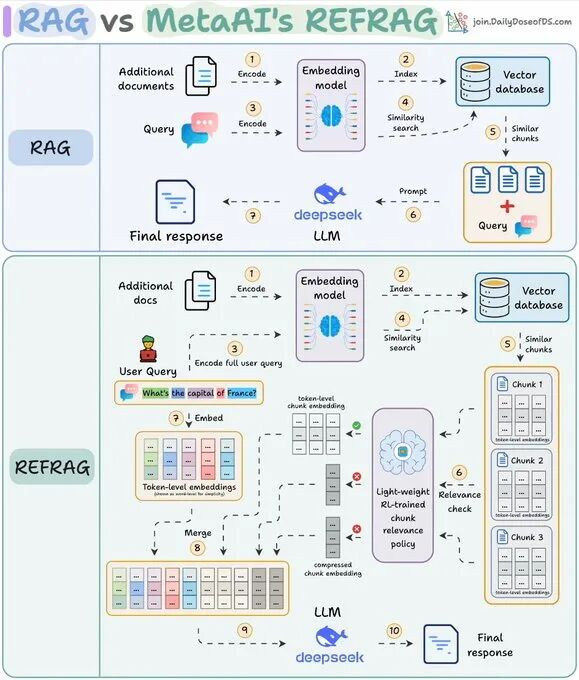
他们刚开源了一个叫 REFRAG 的新 RAG 方案,简单粗暴地说:把无关的上下文压缩到几乎不占地方,只给模型看真正有用的那部分。
实测结果直接看傻人:
- 首token延迟快30.85倍
- 有效上下文窗口扩大16倍
- 处理的token量减少2-4倍
- 在16个主流RAG评测上全面吊打原版LLaMA
这不是小修小补,这是对RAG架构的一次降维打击。
传统RAG为什么这么“废”?
我们现在用的RAG基本都是这个流程:
查询 → 向量检索出Top-K(通常100个)chunks → 全部塞给LLM → 模型一边骂娘一边读垃圾
结果就是:
- 90%的chunk其实没用
- 上下文窗口被灌满,速度暴跌
- 算力账单爆炸
你花的每一分钱,有一大半都在给模型“喂垃圾”。
REFRAG是怎么做到降维打击的?
核心思路只有一个:在把文本塞给LLM之前,就把99%的噪音干掉。
它完全不走传统的“全文本硬塞”路线,而是先在embedding层面动刀:
- 每个chunk被压缩成一个极短的向量(就一个token那么点成本)
- 一个用强化学习(RL)训练的策略网络,对这堆压缩向量快速打分
- 只把分数最高的几块解压还原成完整文本
- 其余低分chunk继续保持“压缩态”(几乎不占token)或者直接扔掉
- 最后:高质量完整chunk + 海量压缩向量一起喂给LLM
模型看到的是:
- 真正相关的几段原文(完整无损)
- 几千个“背景氛围感”压缩向量(提供全局语义,但几乎不花钱)
相当于给模型配了个超级聪明的前置过滤器,它只用读重点,其他的用“压缩包”糊一下就行。
真实效果有多离谱?
官方测了,同样的硬件,同样的模型:
| 方案 | 首token延迟 | 上下文容量 | token消耗 | 16项RAG基准准确率 |
|---|---|---|---|---|
| 传统RAG | 1x | 1x | 1x | 基准 |
| REFRAG | 30.85x快 | 16x大 | 2-4x少 | 全面超越 |
这意味着你可以用原来1/30的延迟、1/4的成本,把上下文窗口从4k/8k直接拉到64k甚至更高,而且准确率还涨了。
这对我们普通人意味着什么?
- 长上下文应用彻底放飞:100万字文档问答?以前卡死,现在随便跑
- 企业级RAG成本暴降:原来一天几万刀的推理费用,可能直接降到几千刀
- 开源即用:Meta已经把代码和模型全扔GitHub了,想玩的直接冲
写在最后
RAG从诞生那天起,就被“上下文垃圾”这个问题死死卡住脖子。
今天,Meta直接一巴刀把这个脖子砍断了。
REFRAG告诉我们:不是上下文不够长,而是我们以前太蠢,不会挑重点。
未来属于会“精打细算”的RAG,而REFRAG就是第一个真正做到的人。
论文地址:https://arxiv.org/pdf/2509.01092
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。