连续拍出5分钟、甚至更长的电影,并且保证画面连贯、动作合理、色彩一致?
最近,美团的LongCat-Video视频生成模型正式上线,它不仅能在文生视频、图生视频任务上达到开源SOTA(State-of-the-Art)水平,更关键的是,它能在5分钟级别的长视频生成上保持稳定输出,且无质量损失。

这意味着,AI不再只是“拼凑片段”,而是真正开始理解物理世界、时空逻辑和场景演化——也就是我们常说的“世界模型”。
作为一个每天都在试用各类AI工具的产品经理,我最大的感受是:LongCat-Video不是又一个视频生成模型,而是AI迈向“预演未来”的第一步。
核心能力
1. 统一模型架构
大多数视频生成模型都只能做单一任务,比如文生视频或者图生视频。但LongCat-Video采用了基于Diffusion Transformer(DiT)架构的多功能统一基座模型,用一个模型就能搞定:
-
文生视频(无参考图,纯文本输入)
-
图生视频(输入一张图,生成动态视频)
-
视频续写(基于已有视频帧,继续生成后续视频)
关键创新是“条件帧数量”来区分任务:
-
文生视频:无条件帧
-
图生视频:输入1帧参考图
-
视频续写:输入多帧前序内容
这意味着,开发者无需为不同任务训练多个模型,一套系统就能完成从创意到长视频的完整流程。
2. 文生视频
-
能精准理解文本中的物体、人物、场景、风格,比如“夕阳下的城市,车流穿梭,赛博朋克风格”。
-
生成视频语义对齐度高,画面细节丰富,开源领域SOTA级别。
3. 图生视频
-
参考图的主体属性(猫还是狗)、背景关系(城市还是森林)、整体风格(写实or漫画)都能严格保留。
-
动态过程符合物理规律,比如“风吹树叶”会有自然的摆动,而不是“乱飞”。
-
支持详细指令、简洁描述、甚至空指令(直接输入一张图,AI也能生成合理动态)。
4. 视频续写
这是LongCat-Video最核心的优势——原生支持分钟级长视频生成。
-
基于多帧条件帧续接视频,无需拼接,避免色彩漂移、画质降解、动作断裂。
-
通过Block-Causual Attention + GRPO后训练,保障跨帧时序一致性与物理运动合理性。
-
实测5分钟长视频,无质量损失,行业顶尖水平。
技术突破
视频生成最大的痛点是:时长越长,质量越差。LongCat-Video通过三大优化,打破了“时长与质量不可兼得”的瓶颈。
二阶段粗到精生成(C2F)
第一阶段:先生成480p、15fps的“草稿”视频(计算量低)。
第二阶段:用LoRA精调模块超分至720p、30fps(提升细节)。
效果:降本提效,同时优化画面细节。
块稀疏注意力(BSA)
将3D视觉token分块,只计算关键top-r块的注意力,计算量降低至标准密集注意力的10%以下。
支持并行训练,进一步提升大模型训练与推理效率。
模型蒸馏优化
结合Classifier-Free Guidance(CFG)与一致性模型(CM)蒸馏,将采样步数从50步减至16步。
效果:推理速度提升10.1倍,效率与质量平衡。
通俗解释:就像你画画,先快速勾线稿(草稿),再精细上色(优化)。AI也学会了“先粗后精”,既省时间又保证质量。
实测效果
LongCat-Video 的模型评估围绕内部基准测试和公开基准测试展开,覆盖 Text-to-Video(文本生成视频)、Image-to-Video(图像生成视频)两大核心任务,从多维度(文本对齐、图像对齐、视觉质量、运动质量、整体质量)验证模型性能:
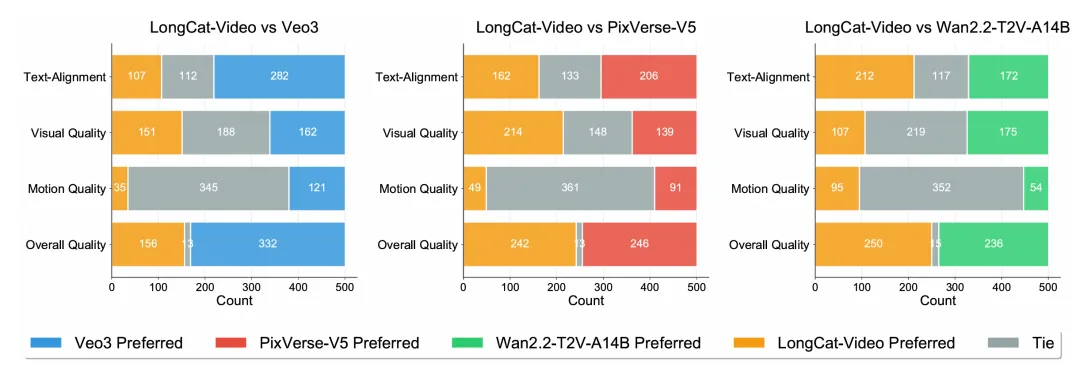
文生视频、图生视频综合能力达到开源SOTA。
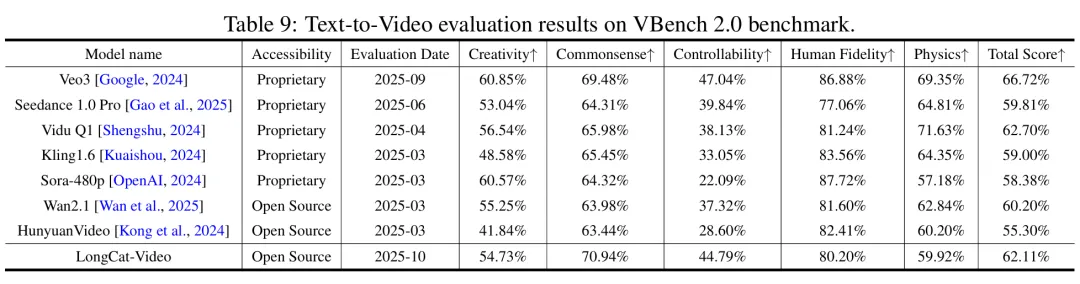
在VBench等公开基准测试中表现优异,尤其在文本对齐度、运动连贯性上优势显著。
总结
LongCat-Video的发布,不仅是视频生成技术的突破,更是“世界模型”探索的关键一步。

为什么?
视频是物理规律、时空演化、场景逻辑的载体。
通过视频生成,AI能压缩几何、语义、物理等知识,在数字空间中模拟、预演真实世界。
长视频能力,让AI可以模拟自动驾驶、具身智能、数字人等深度交互场景。
简单说,LongCat-Video让机器学会了“预演未来”,而这,正是下一代AI的核心能力。
GitHub:https://github.com/meituan-longcat/LongCat-Video
Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Video
项目官网: