大模型的强化学习训练走过了三个阶段:RLHF 告诉模型人类喜欢哪种回答,Reasoning RL 训练思维链(o1、DeepSeek R1),而现在正在发生的第三个阶段目标更大——训练模型在真实环境里持续行动的能力。这就是 Agentic RL:让 RL 的优化对象从一次回答,变成一个完整的 Agent 行为序列。
为什么单轮 RL 撑不住 Agent 场景
传统 RLHF 的流程只有四步:Prompt → Model → Answer → Reward。它建立在一个隐含假设上:一次交互完成一件事。但在真实的 Agent 场景中,写代码、做研究、操作浏览器需要持续几十步甚至几百步的交互,每一步都改变环境状态,而环境状态又影响下一步。
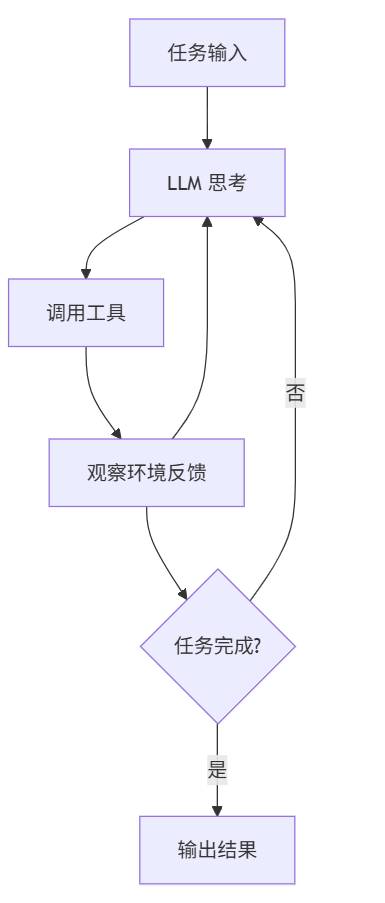
单轮 RL 只能为 Loop 的"输出结果"打一次分,但整个过程中模型做了几十个决策——工具调用、规划路径、错误纠正——这些都得不到训练信号。
MDP 里发生了什么变化
MDP(马尔可夫决策过程)包含五个要素:State、Action、Transition、Reward、Policy。传统 LLM RL 是一个高度退化的 MDP:State 是 Token 上下文,Action 是预测下一个 Token,Reward 在序列末尾给一次。整个训练过程在语言空间内自循环,从未接触外部世界。
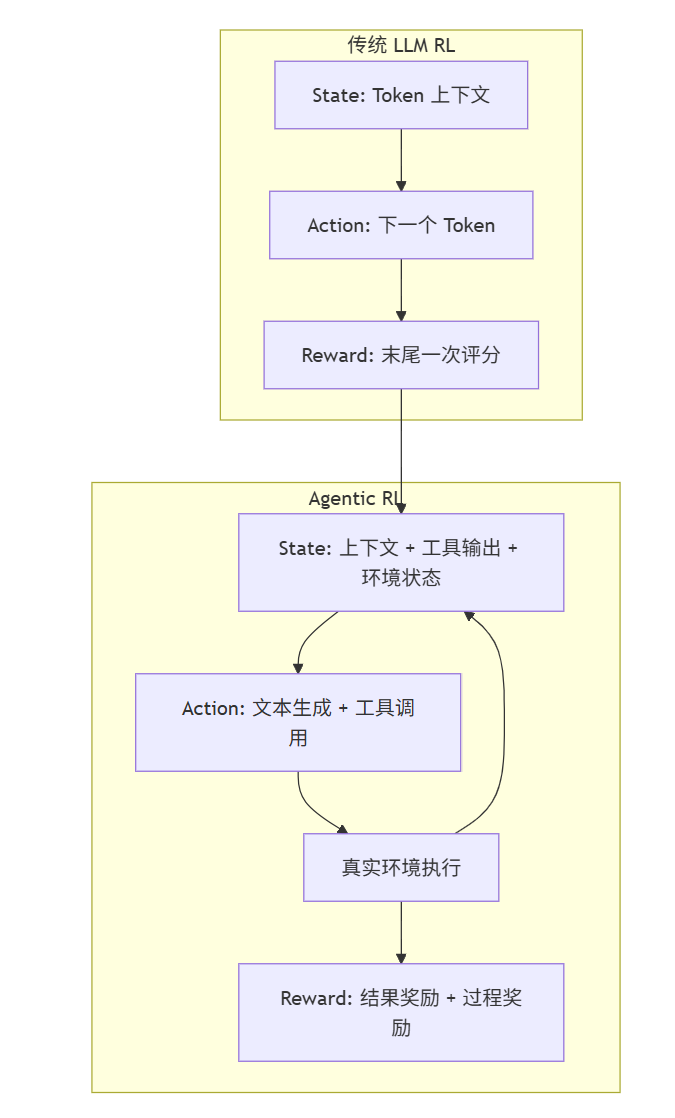
Agentic RL 把这三个要素都扩展了:State 现在包含环境的真实状态,Action 会触发真实的代码执行或文件修改,Reward 需要在几十步的时间跨度里传播。更准确地说,这是一个 POMDP——模型永远只能看到环境的部分状态,必须在信息不完整的情况下做决策。
训练一个 Agent 需要什么基础设施
Agentic RL 的工程难度比同等规模的单轮 RL 高出不止一个量级,根源在于:每条训练样本都需要一个可执行的真实环境。
传统 RL 批量采样 512 个 Prompt,并行跑,收数据,更新。Agentic RL 的 512 个并行 Rollout,每个都需要独立的文件系统、代码执行环境、数据库状态。环境共享会导致状态污染,因此沙箱化是硬性要求。AgentGym-RL 论文记录:尝试并行启动 512 个 Docker 容器训练,Docker Daemon 直接崩溃,最终迁移到 Kubernetes 调度才解决扩展问题。
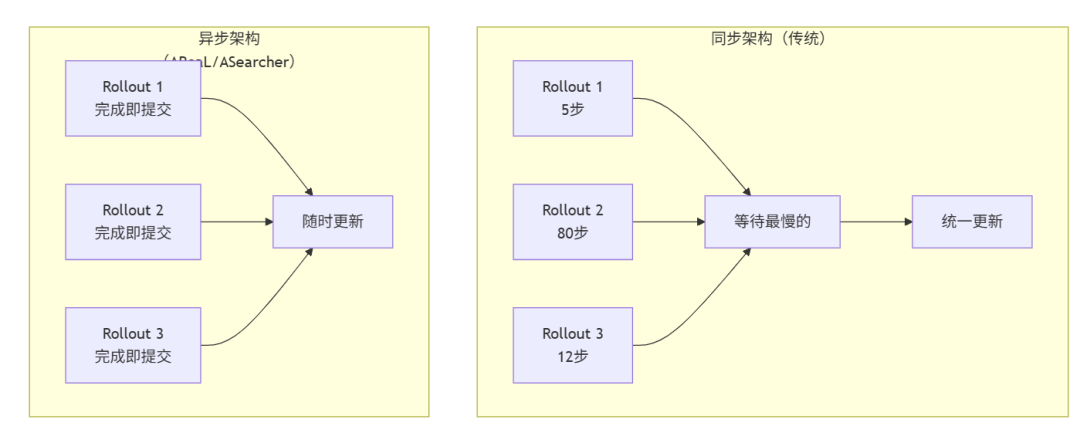
另一个瓶颈是长 Trajectory 的同步等待。100 步的 Rollout 可能需要几十分钟,同步批次下 GPU 要等最长 Trajectory 跑完才能更新——大部分时间空转。2025 年出现的全异步训练架构(ASearcher、AReaL)将 Trajectory 执行与模型参数更新完全解耦,让工具调用超过 100 轮、生成超过 400K Token 的极长任务成为现实。
三个代表性框架
ToRL:让模型自己发现工具的价值
ToRL(Tool-integrated RL)的出发点很简单:工具使用能力用 SFT 教不出来,因为 SFT 只能模仿示例,无法让模型理解"什么时候调工具比自己算更合适"。训练结果验证了这一点:训练前工具使用率约 40%,训练后上升到 80% 且持续增长。
ToRL 的一个设计细节是保留所有错误信息——代码执行遇到 NameError 或 SyntaxError 时,报错原样返回给模型,让模型形成真正的 Self-Correction 循环:读取具体报错 → 定位问题 → 修复代码 → 重试。
AgentGym-RL:课程学习与标准化环境
AgentGym-RL 提供统一的 HTTP API 接口,让 WebArena、SciWorld、Browser Agent、Research Agent 等不同任务环境可以接入同一套训练框架。核心算法贡献是 ScalingInter-RL——一种把课程学习应用到 Agentic RL 的训练策略:先在 8 步以内的短任务上训练,再扩展到 12 步,最终训练到 15 步及以上的长任务。先在短任务建立可靠基础,再逐步提升复杂度,训练稳定性显著改善。
Agent-R1:Step-Level MDP
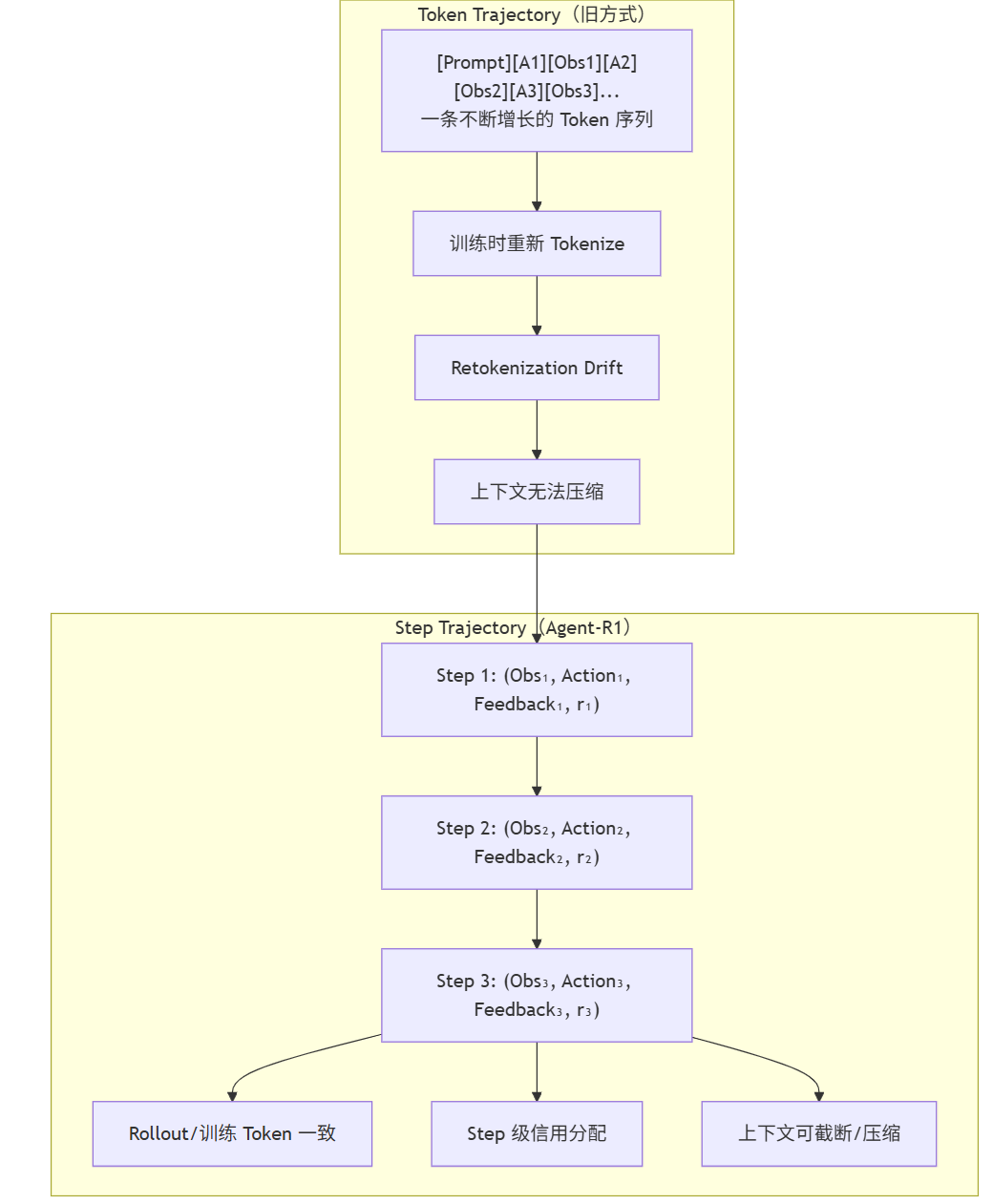
Agent-R1 处理的问题更底层:多步 Agent 训练的数据表示问题。早期的框架把整个交互过程存成一条不断增长的 Token 序列,训练时要重新 Tokenize,会引入细微偏差(Retokenization Drift),且到了第 80 步模型必须背负前 79 步的全部 Token 历史。
Agent-R1 把每一步交互存成独立的 MDP 转移:(Observation_t, Action_t, Feedback_t, Reward_t, Done_t)。这个改变打开了三扇门:上下文可以被截断或压缩、信用分配可以精确到每个 Step、Rollout 与训练使用完全相同的 Token 数据。
2026 年 4 月发表的 StepPO 在此基础上实现了 Step-Level GAE,将价值估计和优势传播对齐到 Step 粒度,在 WebShop、ALFWorld、HotpotQA 等多个基准上取得了一致提升。
信用分配:仍然没有解决的难题
即便有了 Step-Level 的数据表示,Agentic RL 最核心的理论难题依然没有根本解决:长时程信用分配。想象一个 100 步的任务最终失败了——是第 7 步选错工具?第 43 步规划出错?还是第 91 步执行失误?稀疏的结果奖励无法回答这个问题。
目前有三种方向在同时推进:
- Outcome Reward:只用结果奖励,代价是训练信号极度稀疏
- Process Reward Model(PRM):每步给中间评分,信号密集但需要大量人工标注
- iStar(Implicit Step Reward):联合训练隐式 PRM 和策略模型,通过 Trajectory 级别的偏好对比,自动推导每一步的隐式价值,不需要人工标注
- EMPG:根据每步的不确定性动态调节更新幅度,对高置信度的正确行动放大梯度,对不确定的探索步骤抑制梯度
这些方向都指向同一个目标:让训练信号的密度和粒度,匹配 Agent 决策的真实复杂度。
正在收敛的方向
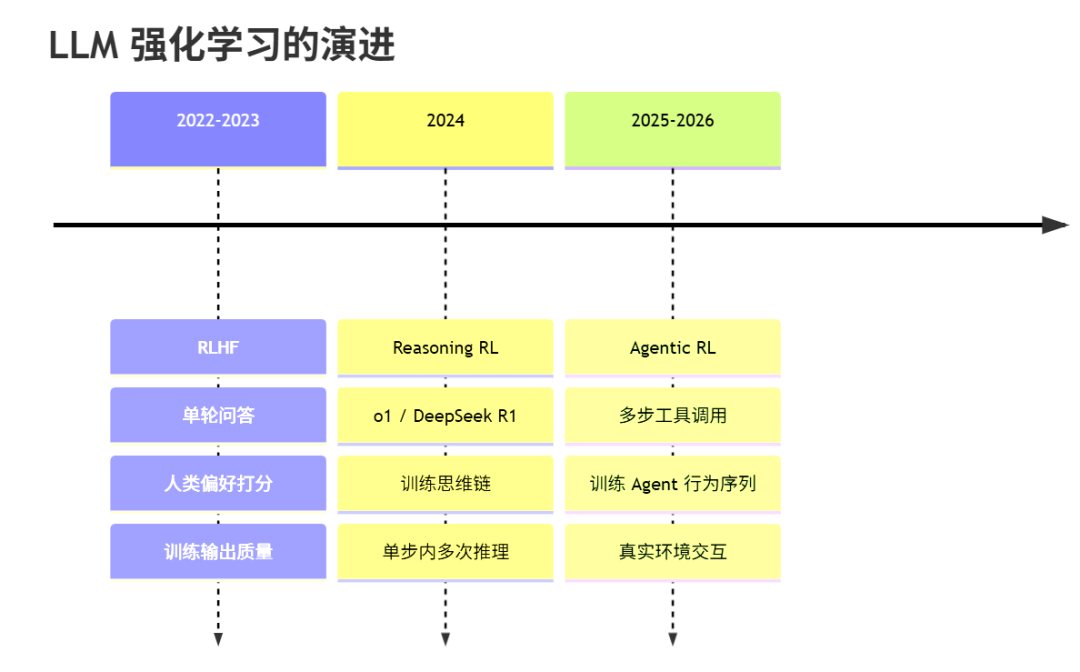
每一阶段的跃迁都是训练目标的扩展:从"输出是否符合偏好",到"推理过程是否有效",再到"在真实世界持续行动的能力是否可靠"。对工程实践的启示是:当 Agentic RL 成为主流,Environment、Skill、Harness、RL Pipeline 的质量,将成为比模型参数量更关键的竞争要素。
苏米注:Agentic RL 的演进轨迹很像软件开发从"手动部署"到"CI/CD"的转变——当训练目标从单次回答扩展到持续行动,基础设施的质量就成了决定性的瓶颈。沙箱化、异步训练、Step-Level MDP 这些看似工程细节的东西,恰恰是 AI 从"能对话"走向"能干活"的关键门槛。