在做 RAG(检索增强生成)项目时,文档解析往往是最让人头疼的环节。传统方案要么速度慢,要么解析效果差——多栏排版混乱、表格结构丢失,更让人担心的是很多服务需要先将文件上传到云端,隐私数据的安全性难以保障。
LlamaIndex 开源的 LiteParse 提供了一个轻量级解决方案:不到 5MB 的安装体积,完全本地运行,解析速度比传统工具快 10-100 倍。目前 GitHub 上已有 10,000+ Star。
GitHub 仓库:https://github.com/run-llama/liteparse
核心能力
空间文本解析:Grid Projection 技术
传统 PDF 解析器将多栏排版、表格和复杂布局变成无意义的文本流。这是因为 PDF 存储的是字符位置,而非逻辑阅读顺序。
LiteParse 的 Grid Projection 技术用算法恢复空间关系,将每个文本元素投射到虚拟网格上。大模型读到的不再是混乱的文字,而是保留了原始布局和结构的内容。

精确边界框输出
每个文本元素都附带精确的边界框坐标(x1, y1, x2, y2)。这在 RAG 分块、图表区域识别和多模态推理中非常有用。

选择性 OCR:只在必要时触发
传统 OCR 方案对所有页面进行扫描,速度极慢。LiteParse 的策略是:
- 1. 首先使用 Google PDFium 提取原始文本
- 2. 仅在页面无文本或字符映射错误时触发 OCR
- 3. 内置 Tesseract OCR,零配置即用
- 4. 支持 EasyOCR、PaddleOCR 等外部引擎
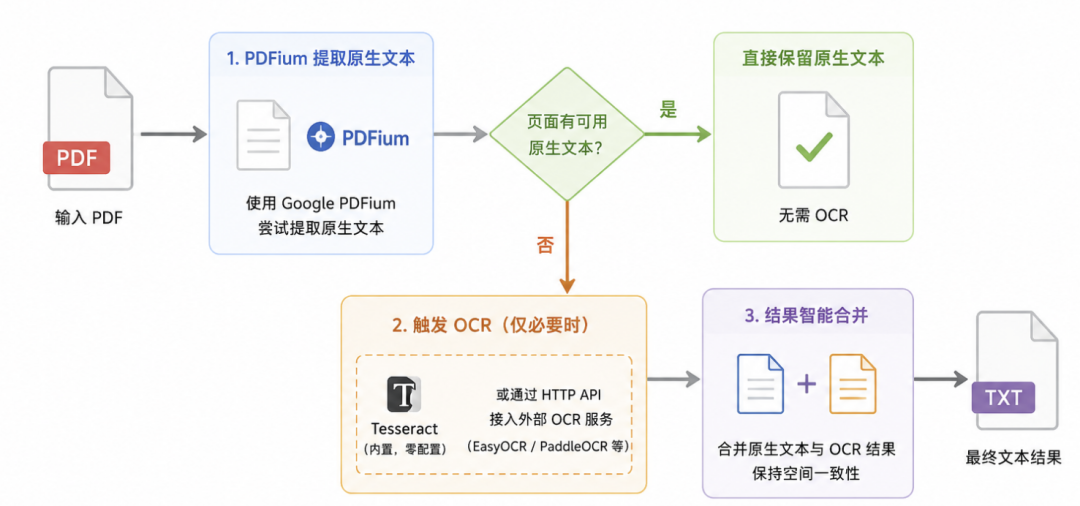
OCR 结果与原始文本智能合并,保证空间一致性。这种设计使处理混合内容 PDF 时效率大幅提升。
性能表现
官方 benchmark 数据:
- • 457 页 100MB 文档:0.777 秒解析完成
- • 20 页 PDF:普通 MacBook 约 3 秒
- • 社区反馈:复杂文档比 PyPDF、PyMuPDF 快 10-100 倍

与 VLM-based 方案相比,延迟显著更低,成本更可控。完全本地化运行,无需 API Key,无需上传云端。
多格式支持
除 PDF 外,还支持 Office 文档(Word、PPT、Excel)和图片格式。通过 LibreOffice 和 ImageMagick 自动转换为 PDF 后解析。
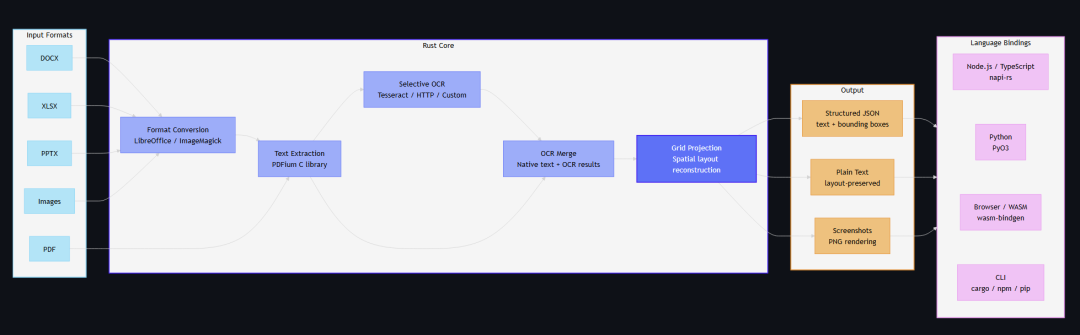
输出格式包括:
- • Markdown:保留标题、表格、列表、图片和链接
- • JSON:包含页面信息、文本项、边界框、字体元数据
- • 纯文本:保留布局,适合简单场景
页面截图生成
一条命令即可生成高分辨率 PNG 截图,为多模态 Agent 提供视觉推理能力。

安装与使用
安装
# Node.js
npm i -g @llamaindex/liteparse
# Python
pip install liteparse
# Homebrew (macOS/Linux)
brew install liteparse基本使用
# 解析 PDF
lit parse document.pdf
# 输出 JSON(含边界框)
lit parse document.pdf --format json -o output.json
# 批量处理
lit batch-parse ./input ./output浏览器端还有 WASM 版本,无需安装即可体验:https://www.llamaindex.ai/liteparse-demo
已知限制
LiteParse 明确表示不支持表格语义分割和图像识别——这些是 LlamaParse 的功能。对于包含复杂表格、多栏排版、图表、手写体或纯扫描 PDF 的文档,可能需要使用 LlamaParse 或其他更强工具。
苏米注:LiteParse 的定位很清晰——不追求全能,而是把"快速、本地、轻量"做到极致。对于大多数常规 PDF 解析场景(技术文档、论文、报告),它的 Grid Projection 技术已经能保留足够的结构信息。RAG 项目中,文档解析往往是瓶颈,LiteParse 用不到 5MB 的体积换取了 100 倍的速度提升,这种取舍是务实的。