作为一名常年跑新模型、做选型评测的产品经理,如果只把 LMArena 视为一个查看“公开模型对比平台”,那你就错了。
普通用户可以在这里薅羊毛。
你可以免费体验 GPT-5.2、Gemini 3 Pro、Claude Opus 4.5、Grok 4.1,还有 DeepSeek、智谱、MiniMax 这些国产大佬。
图像模型,可以免费用 Nano Banana Pro、GPT-Image-1.5 和 FLUX 2。
不过,免费试用不等于适合上生产,我在文末会给出明确的适配建议。
平台概览与定位
平台名称与网址:LMArena(lmarena.ai),前身为 Chatbot Arena。

核心方法:基于“真人偏好”的盲测投票。用户输入问题,平台随机分配两个匿名模型作答;用户仅凭回答质量投票,随后才显示模型身份。
排名机制:采用类似国际象棋的 Elo 评分。每次对决产生加减分,累计形成榜单。
题目来源:全球用户的真实提问(平台披露为覆盖多国、多语言),减少“刷榜”与过拟合标准试卷的影响。
定位与商业模式:对公众试用免费;企业可付费做定制化评测(含盲测、报告、榜单展示等)。关于融资与估值、营收等媒体报道数据存在时间差与版本差异,建议以平台官方披露为准;对普通用户而言,“测与榜单”目前无需付费。
当前可用模型覆盖
LMArena已从纯文本对话扩展到多赛道。
下列信息结合平台公开描述与社区共识,部分模型在平台内可能使用别名或代号:
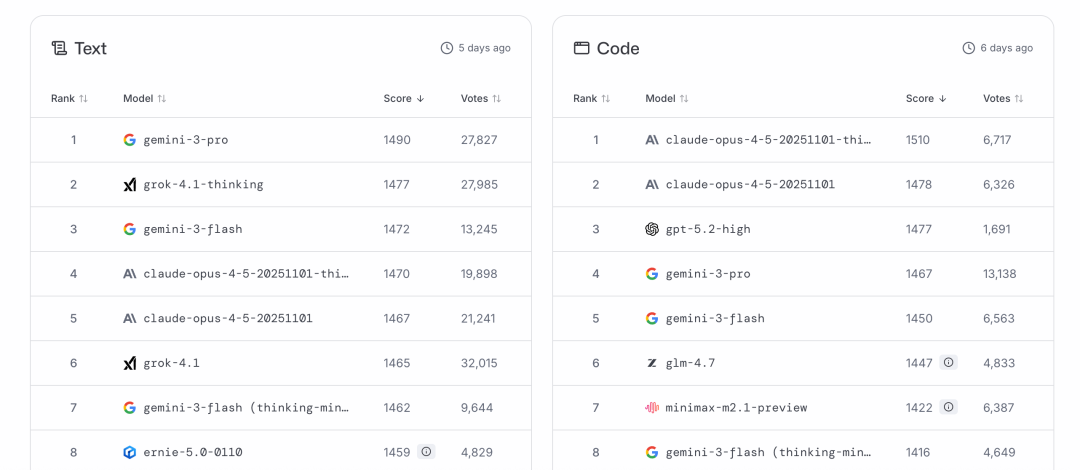
- Text Arena(文本对话):可试用多家通用大模型,如平台内标注的 GPT-5.2、Gemini 3 Pro、Claude Opus 4.5、Grok 4.1、DeepSeek R1、GLM-4.7 等。
- Vision Arena(看图说话):支持多模态理解,平台显示谷歌系列在此赛道表现突出。
- Code Arena(编程生成,曾称 WebDev Arena):用于代码生成与网页组件产出,平台显示 Anthropic 系列高阶模型在该赛道长期居前。
- Text-to-Image Arena(文生图):平台标注支持 GPT-Image-1.5、FLUX 2、Ideogram 3 以及国内模型如腾讯 Hunyuan Image 3.0、字节 Seedream 4.5。
- Image Edit Arena(图像编辑):支持局部/整体编辑,平台显示 OpenAI 与谷歌系列交替居前,曾出现 Nano Banana Pro(社区俗称“大香蕉”)为图像方向代号。
- Video Arena(文生视频):新近上线网页端,平台列出 Veo 3.1、Sora 2、可灵 2.6 Pro、Seedance v1.5 Pro、Wan 2.5、Hailuo 2.3 等多模型。需登录后使用。
说明:平台存在“新模型匿名试测”的长期惯例。
比如社区曾观察到 OpenAI 的 GPT-5 代号“summit”,Gemini 图像方向代号“nano-banana”等。
不同时间段、不同区域用户可能遇到不完全一致的模型名单与别名。
功能范围、技术特征、使用门槛与适合人群
| 赛道/功能 | 技术特征 | 使用门槛 | 适合场景 | 常见限制 |
|---|---|---|---|---|
| Text Arena(文本对话) | 盲测投票、Elo排名、多语言 | 无需注册即可体验 | 通用问答、创意写作、知识检索初步对比 | 需投票才能继续;响应速度可能慢于官方 |
| Vision Arena(看图说话) | 图像理解与描述、指令遵循 | 上传图片即可;对大图可能有尺寸限制 | 多模态问答、文档/图表说明 | 图像隐私需谨慎;复杂OCR/计算图表不保证稳定 |
| Code Arena(编程生成) | 代码生成与网页产出、自动评分 | 提示词设计需更精确 | 跨模型对比编码风格与正确性 | 环境与依赖不在同一沙盒;生产级质量需另行验证 |
| Text-to-Image(文生图) | 风格化与构图控制、模型多样 | 编写提示词;可能支持负向提示 | 海报、插图、概念草图 | 版权与商用条款随模型不同;高分辨率/一致性需要迭代 |
| Image Edit(图像编辑) | 局部修复、重绘、风格迁移 | 上传原图并给出编辑意图 | 电商修图、社媒素材处理 | 细粒度控制有限;复杂遮罩需手工 |
| Video Arena(文生视频) | 短视频生成、风格与场景指令 | 需注册登录;提示词设计门槛较高 | 创意分镜验证、模型能力摸底 | 时长/分辨率有限制;下载格式与配乐能力因模型而异 |
价格、配额与策略
- 公众使用:当前文本与图像相关赛道可直接免费使用;视频生成需登录,注册免费。
- 配额与速率:平台存在速率限制与人机验证;高峰期响应速度可能低于模型官方接口。
- 企业评测:提供付费评测与报告服务,按项目定制与报价;用于模型对比、采购前选型、特定任务盲测等。具体价格以官方商务沟通为准。
- 模型价格与参数:平台中的模型常以别名或匿名形式出现,且由各厂商提供。若需商用接入,请以模型官方渠道的定价与API规格为准(如上下文长度、调用费用、速率限制、图像/视频分辨率与时长、输出许可条款等)。
如何使用:三种模式
- Battle(默认):输入问题 → 系统随机分配两模型作答 → 根据质量投票 → 揭晓身份。适合摸底整体能力、体验“盲测”。
- Side-by-Side:在左上角选择手动PK两模型(如 GPT-5.2 vs Claude Opus 4.5)。适合有明确备选的对比场景。
- Direct Chat:选择单个模型直接聊天或生成内容。适合连续探索与提示词调试。
图像/视频:在输入框下选择“图像”按钮进行文生图或图像编辑;
视频访问 lmarena.ai/video,输入提示词即可生成并下载。视频功能需登录。
结语
如果你是产品或技术负责人,需要在短时间摸清主流与新模型的能力区间,LMArena的盲测与Elo榜单是一个成本极低的前哨工具:用Battle快速感知整体质量,用Side-by-Side缩小候选范围,用Direct Chat打磨提示词。
随后,将少量入围模型带到你自己的数据与流程中做可控评测,确认成本、合规与SLA,再决定采购与接入。
对普通用户而言,LMArena提供了“免费试用多模型”的窗口,但它的本职是评测与榜单。
把它用在探索与比较上,价值最大;把它当作生产力平台,风险超出收益。
理清定位,按场景选择,你会在这个“真人偏好”的试用台上得到比跑分更接近真实使用的参考。
官网地址:lmarena.ai
部分地区需要网络支持