最近在浏览开源AI项目时,我注意到一个有趣的现象:大多数AI框架都在追求"大而全",但真正在生产环境中落地的中小团队,往往被这些重型框架的学习曲线和复杂依赖所困扰。
直到我发现了n-skills这个项目,才意识到有些框架的价值恰好在于它的"克制"——用最小化的依赖和清晰的抽象,解决AI应用开发中最实际的问题:技能碎片化和重复造轮子。
今天我想通过拆解这个项目,和各位分享它为什么值得关注。
什么是n-skills,它解决什么问题
n-skills是一个开源的AI技能模块化框架,核心解决的是:AI能力在应用开发中的碎片化问题。

在实际的AI应用开发中,我们经常面临这样的局面:
- 文本生成调用OpenAI API的方式A
- 语音识别调用本地模型的方式B
- 数据分析依赖自定义逻辑的方式C
- 多个能力要串联执行时,需要手写复杂的调度和依赖处理
结果就是:每个新项目都要重新适配不同的AI能力接口,不同技能之间难以高效协同,开发效率大打折扣。
n-skills的思路是把所有AI能力标准化封装成可插拔、可组合的"技能模块",让开发从"从零造轮子"变成"拼积木"。
核心功能梳理
1. 技能模块化封装
框架定义了统一的Skill基类,所有AI能力(无论是大模型API调用、本地模型推理,还是自定义数据处理逻辑)都必须遵循同一套接口规范——包括初始化、执行和结果返回。这样做的好处是:
- 屏蔽底层差异,上层代码只需面向Skill接口编程
- 减少适配代码,新增技能只需实现基类方法
- 便于测试和维护,每个技能都是独立的单元
2. 技能编排与协同
支持通过配置(而非代码)将多个技能串联或并联执行。例如一个客服质检流程可以这样组织:
语音转文本 → 意图识别 → 自动评分 → 异常告警
框架的SkillExecutor负责管理依赖关系和执行顺序,开发者只需定义技能组合,无需手写繁琐的调度逻辑。
3. 轻量级设计
整个框架的代码量精简,核心依赖少,可以无缝集成到既有项目中,不需要大规模重构。这对于团队现有系统的侵入性最小,降低了采用成本。
4. 多环境适配
支持本地单机部署,也能适配云原生环境,满足从开发测试到生产的不同部署需求。
架构设计拆解
n-skills采用了清晰的三层架构设计:
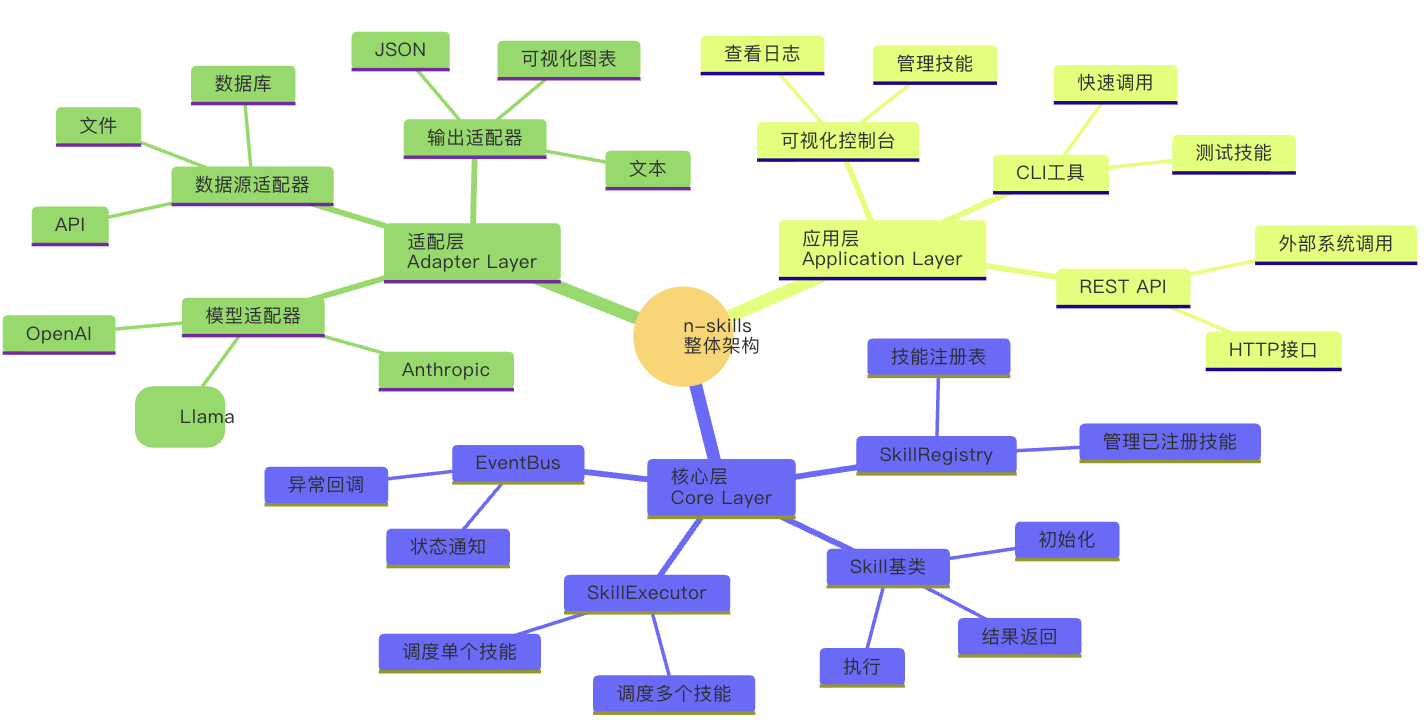
| 层级 | 核心组件 | 职责 |
|---|---|---|
| 适配层 | Model Adapters、Data Connectors | 屏蔽外部依赖差异(不同LLM、数据源),统一输入输出格式 |
| 核心层 | Skill基类、SkillExecutor、SkillRegistry、EventBus | 技能定义、调度执行、注册管理、状态反馈 |
| 应用层 | 具体业务技能、编排配置 | 实现具体业务逻辑,组合技能完成端到端流程 |
关键设计要点:
- 核心抽象:Skill基类是框架的"心脏",统一定义了所有技能的接口规范。这个设计保证了技能的可复用性和互操作性。
- 调度逻辑:SkillExecutor通过SkillRegistry查找技能、通过EventBus反馈状态,完全解耦了调度逻辑和技能实现,使框架具有高扩展性。
- 适配模式:通过适配层统一不同模型和数据源的接口,避免了核心层对具体实现的依赖,符合开闭原则。
应用场景与适配人群
| 应用场景 | 具体例子 | 核心价值 |
|---|---|---|
| 中小团队AI应用快速开发 | 客服问答机器人、内容生成工具 | 缩短原型开发周期,减少基础设施学习成本 |
| 企业AI能力中台建设 | 内部NLP、CV、数据分析技能库 | 避免各部门重复开发,统一技能管理 |
| 个人开发者工具整合 | 将多个AI能力组合成个人生产力工具 | 低门槛实现AI应用,快速迭代想法 |
| 高校AI教学与实验 | 学生快速实验不同AI技能的组合逻辑 | 降低框架学习曲线,聚焦算法逻辑 |
优缺点客观评估
优势:
- 轻量化&易上手:源码简洁,注释清晰,即使没有框架使用经验的开发者也能快速理解核心逻辑。
- 扩展性强:Skill基类设计灵活,自定义技能只需继承并实现执行逻辑,无需修改框架代码。
- 无厂商锁定:支持对接不同大模型和数据源,不绑定任何特定服务商,降低迁移成本。
- 学习价值高:框架设计思路清晰,可作为学习软件设计模式(工厂模式、观察者模式)的优质案例。
局限性:
- 企业级功能缺失:暂无权限管理、高并发调度优化、分布式执行等企业级特性,不适合超大规模部署。
- 生态相对薄弱:相比LangChain等成熟框架,社区贡献的预制技能较少,需要自己实现业务特定的技能。
- 文档不够完善:部分高级功能(如复杂编排配置)缺少详细文档和最佳实践指南,需要查看源码。
- 监控和调试工具不足:缺少可视化的技能执行流程图、性能分析工具等。
部署与快速上手指南
前置要求:
- Python 3.8+
- pip 包管理工具
- Git(可选)
第一步:克隆项目并创建环境
git clone https://github.com/numman-ali/n-skills.git
cd n-skills
# 创建虚拟环境
python3 -m venv venv
source venv/bin/activate # Linux/Mac
# 或 venv\Scripts\activate # Windows第二步:安装依赖
pip install -r requirements.txt第三步:配置环境变量(以OpenAI为例)
export OPENAI_API_KEY=your_api_key_here # Linux/Mac
# 或在Windows中通过系统设置配置第四步:编写并运行第一个技能
cat > test_skill.py << 'EOF'
from n_skills.core.skill import Skill
from n_skills.core.executor import SkillExecutor
# 定义自定义技能
class HelloAISkill(Skill):
def __init__(self):
super().__init__(name="hello_ai")
def execute(self, input_data: str):
return f"AI回复: {input_data} - 由n-skills执行"
# 注册并执行
if __name__ == "__main__":
executor = SkillExecutor()
hello_skill = HelloAISkill()
executor.register_skill(hello_skill)
result = executor.execute_skill("hello_ai", input_data="你好,n-skills!")
print(result)
EOF
python test_skill.py进阶配置建议:
- 在生产环境中,建议将API Key等敏感信息存储在环境变量或密钥管理服务中。
- 可以通过修改配置文件来切换不同的LLM提供商(OpenAI、本地Llama等)。
- 如需在多个技能间共享状态,可以使用EventBus进行解耦通信。
类似项目对比参考
如果你在评估是否采用n-skills,这个对比可能有帮助:
| 项目 | 定位 | 学习曲线 | 企业级支持 | 适合场景 |
|---|---|---|---|---|
| n-skills | 轻量技能模块化框架 | 低 | 弱 | 中小团队、快速原型、学习用途 |
| LangChain | LLM应用编排框架 | 中 | 中 | 复杂LLM应用、生态集成需求 |
| Apache Airflow | 工作流编排 | 高 | 强 | 大规模数据流程编排、分布式调度 |
| Ray | 分布式计算框架 | 高 | 强 | 大规模并行处理、分布式训练 |
总结
在我看过的众多AI开源框架中,n-skills并不以功能的全面性著称,但我认为它的价值恰好在于此——它用最少的复杂度,解决了最实际的问题。