在体验过众多AI音频产品后,我发现大多数付费服务都存在字数限制、播放延迟或功能受限的问题。
最近接触到的开源项目EasyVoice让我眼前一亮——它以完全开源、无字数限制、流式传输等特性,为文本转语音领域提供了一个实用的替代方案。
这篇文章将从产品经理的角度,逐一拆解这个项目的核心价值。
项目概述
EasyVoice是一款开源文本转语音解决方案,定位于提供本地可部署、功能完整的TTS(Text-To-Speech)工具。
相比商业服务,它的主要差异化特征包括:
- 无限制文本处理:支持10万字以上内容一次性转换,适配长篇小说、完整视频脚本等场景
- 流式传输技术:音频生成过程中即可播放,无需等待全部完成
- 完全开源部署:支持本地或私有云部署,数据自主掌控
- 零成本使用:无字数限制费用、无订阅制,基于开源模型运行
核心功能模块
1. 文本转语音与自动字幕生成
该功能涵盖两个产出物:
- 自然流畅的语音输出(MP3/WAV格式)
- 自动对齐的字幕文件(SRT/VTT格式),直接可用于视频编辑软件(Premiere、DaVinci等)
这种"双出"设计减少了内容创作者的后期处理工作量,特别适用于视频配音、字幕翻译等工作流。
2. 多语言与多角色配音
支持的语言覆盖中文、英文等主流语言。更具特色的是多角色配音能力——用户可为同一段文本中的不同角色分配不同声音、语速、音调,实现小说改编、动画配音等专业级效果。
3. AI智能推荐配音
系统可基于输入文本的情感倾向、内容类型自动推荐最适配的声音配置,降低新用户的决策成本。这对非专业用户快速上手有帮助。
4. 细粒度参数调节
支持对以下参数的百分比级精准控制:
- 语速(Rate):-100% 至 +100%
- 音调(Pitch):-100Hz 至 +100Hz
- 音量(Volume):0% 至 100%
这些参数可在生成前通过试听预览进行验证,避免返工。
应用场景
基于功能特性,EasyVoice主要适配以下场景:
| 场景类型 | 使用方式 | 价值体现 |
| 有声书制作 | 长篇文本 + 多角色配音 + 流式预览 | 支持小说全文转换,无字数限制 |
| 视频配音 | 脚本文本 → 音频 + 字幕同步输出 | 字幕与音频自动对齐,减少Premiere手动卡点工作 |
| AI朗读应用 | 本地部署 + API调用 | 保证数据隐私,可集成到自有应用 |
| 内容营销 | 文章/新闻 → 播客音频 | 快速生成音频内容,扩大传播形式 |
安装与部署
EasyVoice提供三种部署方式,满足不同用户的技术水平:
方式一:Docker一键启动(推荐)
适合快速体验和生产环境部署:
docker run -d -p 3000:3000 -v $(pwd)/audio:/app/audio cosincox/easyvoice:latest或使用Docker Compose编排:
git clone git@github.com:cosin2077/easyVoice.gitcd easyVoicedocker-compose up -d优势:环境隔离、开箱即用、易于扩展。
方式二:本地Node.js运行
适合二次开发、功能定制场景:
# 启用 pnpm 包管理器corepack enable# 克隆仓库git clone git@github.com:cosin2077/easyVoice.gitcd easyVoice# 安装依赖pnpm i -r# 开发模式启动pnpm dev:root要求环境:Node.js 16+ 和 pnpm。
方式三:在线Demo
无需本地部署,直接访问 easyvoice.ioplus.tech 即可体验,适合评估项目可行性。
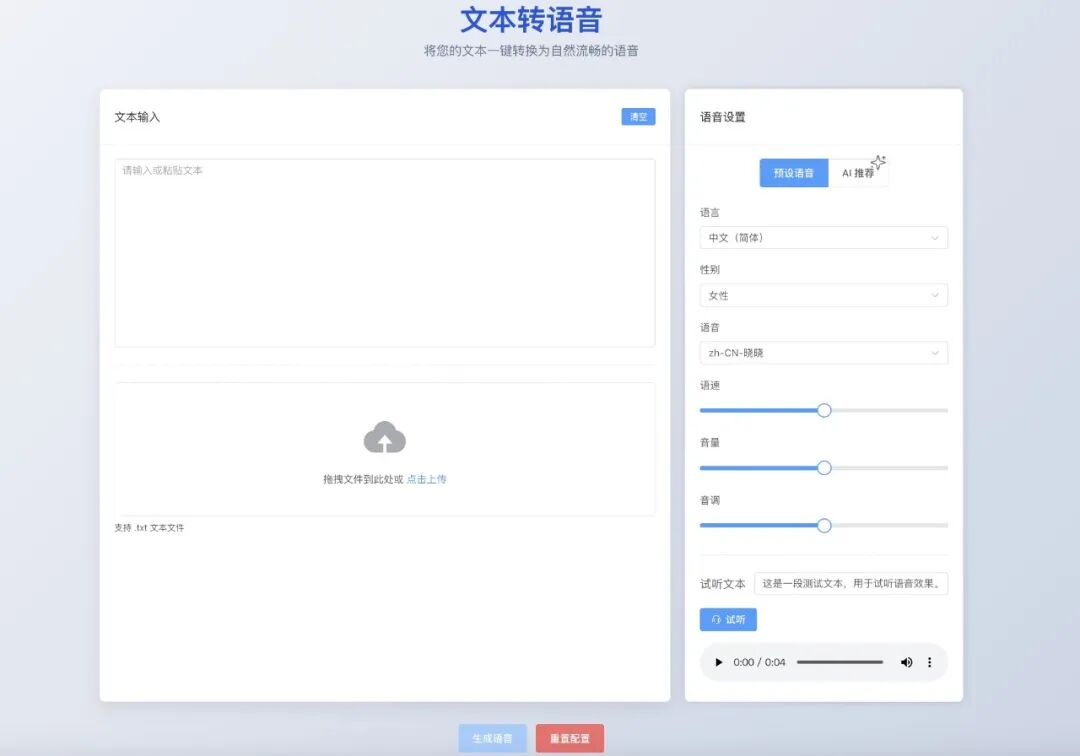
配置管理
项目支持以下配置方向:
- 语音引擎选择:内置支持Microsoft Azure TTS、OpenAI API(兼容所有兼容OpenAI的接口),用户可根据成本、质量需求灵活选择
- 后端服务配置:Node.js + Express架构,支持环境变量配置API密钥、服务端口等
- 音频处理:集成ffmpeg,支持多种音频格式转换与处理
- 存储策略:Docker部署时通过Volume挂载本地存储目录,便于音频文件管理
高级用法:多角色配音实战
以小说朗读为例,展示API调用的多角色配置方式:
curl -X POST http://localhost:3000/api/v1/tts/generateJson \ -H "Content-Type: application/json" \ -d '{ "data": [ { "desc": "徐凤年", "text": "你敢动他,我会穷尽一生毁掉卢家,说到做到", "voice": "zh-CN-YunjianNeural", "volume": "40%" }, { "desc": "姜泥", "text": "徐凤年,你快走,你打不过的", "voice": "zh-CN-XiaoyiNeural" }, { "desc": "旁白", "text": "面对棠溪剑仙卢白撷的杀意,徐凤年按住剑柄蓄势待发...", "voice": "zh-CN-YunxiNeural", "rate": "0%", "pitch": "0Hz" } ] }' \-o output.mp3执行后生成带有角色配音的音频文件,实现小说有声化的专业级效果。
与同类项目的对比
| 项目 | 字数限制 | 多角色配音 | 流式播放 | 部署方式 | 成本 |
| EasyVoice | 无限制 | ✓ 支持 | ✓ 支持 | 本地 / Docker | 免费开源 |
| Azure TTS(商业) | 受限(按字计费) | ✗ | ✓ 支持 | 云端API | 按使用量计费 |
| Google TTS(商业) | 受限 | ✗ | ✓ 支持 | 云端API | 按使用量计费 |
| Elevenlabs(商业) | 受限 | ✓ 支持 | ✓ 支持 | 云端API | 订阅制 / 按量计费 |
EasyVoice在功能完整性和成本效益方面具有竞争力,尤其适合对数据隐私有要求、需要大量文本转换的用户。
技术架构概览
- 前端技术栈:Vue 3 + TypeScript + Element Plus,提供简洁的Web界面
- 后端技术栈:Node.js + Express + TypeScript,支持异步处理与API标准化
- 语音合成引擎:Microsoft Azure TTS(主)、OpenAI API兼容接口(备选),通过ffmpeg进行音频处理
- 容器化部署:Docker + Docker Compose,支持快速水平扩展
总结
作为一名长期关注开源AI工具的产品经理,我认为EasyVoice在以下方面填补了市场空白:
首先,功能覆盖完整——从基础的文本转语音到多角色配音、自动字幕生成,覆盖了内容创作的主要需求链条。
其次,部署灵活且成本低——Docker一键启动的方案大幅降低了技术使用门槛,完全开源免费的模式避免了订阅费用困扰。
再次,流式传输与参数精控——这两项特性使其不仅能处理大文本量,还能提供接近专业音频工具的定制化能力。
最后,数据自主可控——本地部署模式对隐私敏感的企业应用有显著优势。
不过需要注意的是,相比商业产品,EasyVoice的语音自然度、多语言支持、社区活跃度等方面仍有优化空间。适合的用户画像是:有本地部署能力、对成本敏感、追求功能完整性的开发者和内容创作团队。
如果你正在寻找一个可自主控制、功能完整的TTS解决方案,不妨把EasyVoice加入技术栈评估清单。