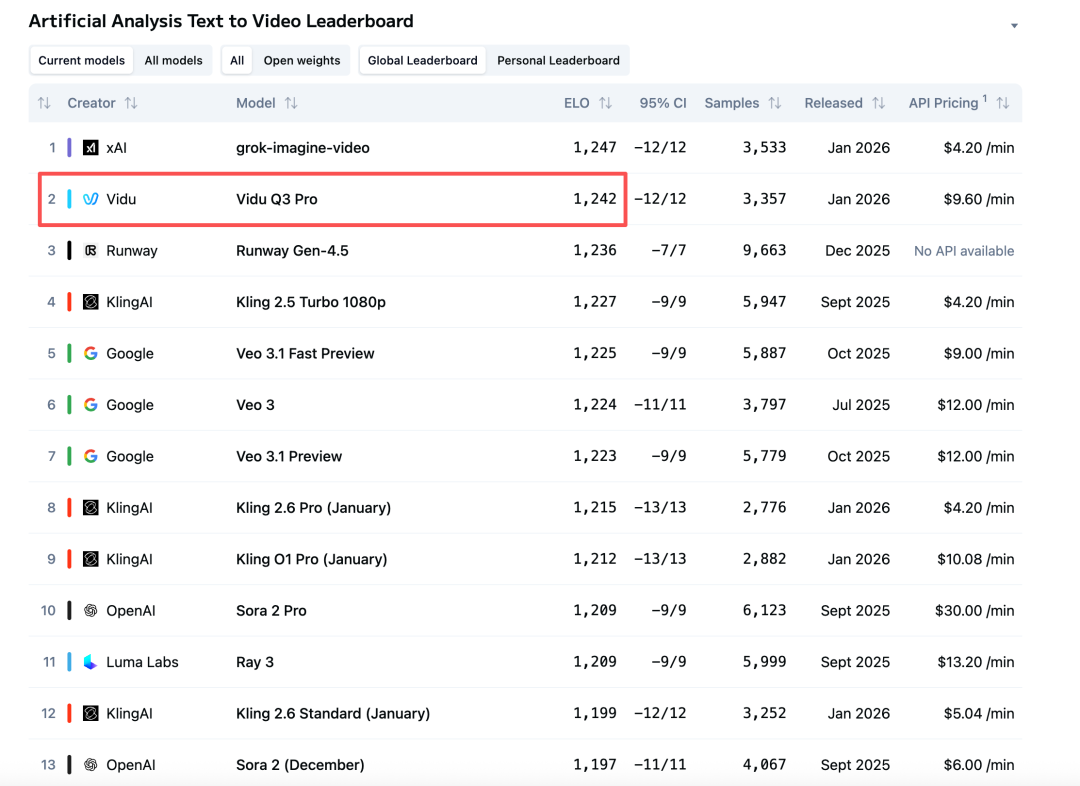
昨天我还在观察国产大模型的进展,今天就在 Artificial Analysis 的 Video Arena 榜单上看到 Vidu Q3 跃至全球第二(国产第一)。
这背后的变化不在某一帧是否惊艳,而是标准从“给你画面”升级到“声画同出、可剪可用”。
榜单与定位:从“素材”到“成片”的转变
根据 Artificial Analysis 的 Video Arena(盲测偏好投票,ELO 排名),Vidu 最新一代商业级视频模型 Vidu Q3 在 Text-to-Video 总榜里 ELO 评分为 1242,全球第二、中国第一,超过了 Runway Gen‑4.5、Google Veo 3.1 和 OpenAI Sora 2,仅次于 xAI 的 Grok Imagine(视频)。
更关键的是,Vidu Q3 将“声画同出”和“单次 16 秒生成”作为默认交付能力,显著降低了二次配音、音乐和镜头重组的成本。
产品形态与核心参数(面向制作)
- 生成时长:单次支持 16 秒直出(相比许多模型的 5–10 秒有明显提升)。
- 音视频:原生音视频同步,支持旁白、双人(多角色)对话、环境音、音乐,强调口型对齐(lip‑sync)。
- 镜头能力:镜头控制与自动切镜;可通过自然语言控制建立镜头、推进、特写、反打,组合成可剪叙事片段。
- 文本渲染:精准渲染中文、英文、日文,适用于字幕、路牌、海报等场景,降低后期重做成本。
- 画质与帧率:官方表述为“高清直出”;实际导出分辨率与帧率随任务与设置而变化(常见在 720p–1080p、24–30 fps 区间)。
- 语言与叙事:支持中/英/日多语提示与对白,强调节奏、停顿与情绪呼吸的生成一致性。
- 接入方式:网页端与开发者平台(API)。
从脚本到“可直接上线”的成片
过去一年测试不同视频模型时,我遇到的主要问题是“只出画面、不出声音”,生成后还要去配音、加音乐、铺环境音。
Video Arena 榜单里不少头部模型被标注为“(No Audio)”,这意味着它们在画面上很强,但交付形态仍偏“素材”。
在 Vidu Q3 的体验中,16 秒声画同出成为明显分水岭:多 1 秒,叙事空间与声音的发挥都会明显增加。以下是我在产品上复现的几个典型脚本片段:
- 都会对话(英文,15 秒):两个女生手拿咖啡在街上漫步。远景城市环境音,中景叹气与对话,特写口型与轻微情绪动作,配乐与环境音自然融合,直出即可用。
- 球场父子对话(中文 UI/英文对白混合):远景建立空间,中景亲子互动,特写表现神态,自动切镜让节奏自然推进,声音层级清晰。
- 三语文字渲染(中文/英文/日文):东京夜景缓推至巨型屏,三语大字稳定切换,字形清晰,扫描线与光溢出细节可用,后期无需重排文字。
- 动画喜剧节奏:固定机位看向烤箱,英文对白 + 夸张但自然的节奏,音效与停顿明确,符合喜剧剪辑点。
- 白噪音循环素材:雨夜窗边、壁炉火焰、木质摇椅,环境声层次稳定,时长可循环,无突兀音量变化,适合直接上线为辅助体验内容。
差异化与适配性:与同类模型的结构化对比
| 模型 | 音频 | 单次时长 | 镜头控制/自动切镜 | 多语文字渲染 | 适配人群与场景 |
|---|---|---|---|---|---|
| Vidu Q3 | 原生声画同出,口型对齐 | 16 秒 | 支持,通过自然语言提示控制 | 中/英/日精准渲染 | 短剧/漫剧、广告片段、社媒成片、白噪音素材、开发者接入 |
| Runway Gen‑4.5 | Video Arena 多版本标注为 No Audio | 多版本策略(公开信息不一) | 支持一定程度的镜头控制 | 文本渲染能力依任务差异 | 创意素材生成、后期合成与剪辑为主 |
| Google Veo 3.1 | 多参考为 No Audio | 研究与受限试用为主 | 研究型镜头/物理一致性 | 未见稳定多语文字直出 | 研究验证、演示级样片 |
| OpenAI Sora 2 | 多参考为 No Audio | 长时生成(公开测试未普及) | 强调物理与时空一致性 | 不以文字渲染为卖点 | 高质量素材与研究演示 |
| xAI Grok Imagine(视频) | 榜单领先,音频能力未公开为主流卖点 | 取决于版本 | 镜头能力强(推测) | 未知/不稳定 | 创意生成与模型能力展示 |
说明:不同平台与版本的功能差异较大,上表以公开榜单描述与主流认知为参考,具体以各产品最新发布与文档为准。
价格与接入
- 账户体系:Vidu 采用账户积分与套餐机制,注册可获得试用积分;
- 使用计费:网页端通常按生成时长、分辨率、是否启用音频等维度消耗积分;API 侧按调用量与输出规格计费。
- 企业方案:支持企业与团队定制套餐、配额与项目制支持。
- 参考入口:官网 与 开发者平台 的价格与计费说明(可能随版本更新调整)。
注:价格体系会随版本迭代与活动变化,建议以官方页面为准。
使用门槛与适合人群
- 提示词设计门槛:需要将镜头、节奏与对白分解到“镜头 1/2/3”或“Beat 1/2/3”的结构化描述;语种与口型需一致。
- 适合人群:短剧/漫剧创作者、社媒与广告制作团队、品牌内容部门、播客与白噪音内容制作者、希望以 API 批量生成的开发团队。
- 工作流建议:
- 先写分镜与对白的 beat sheet(3–5 个镜头,控制在 16 秒内)。
- 明确机位(远景/中景/特写)、光线与音景(环境音、音乐风格)。
- 将需要渲染的文字(字幕、招牌、海报)明确到具体语种与词组。
- 首版生成后,用轻量迭代微调镜头时长与对白口型。
限制与风控(基于测试与行业经验)
- 角色一致性:跨镜头的形象一致与长期剧情角色延续需要额外提示与迭代。
- 细小文字:极小字号或复杂字体在运动与光线复杂场景下可能出现不可读或抖动。
- 物理细节:快速运动、复杂遮挡与极端光影条件下的物理一致性仍需审片与重试。
- 版权与合规:素材、音乐与人像生成需符合平台与地方法规;商用需审查风险与水印策略。
为什么“16 秒与声画同出”是分水岭
大多数模型对分辨率、帧率与稳定性的优化解决了“像不像”的问题,但要从“素材”变成“内容”,声音与节奏必须被纳入默认交付:对白、旁白、环境音、音乐、停顿与情绪的呼吸。Vidu Q3 将这部分作为内建能力,并与镜头控制、自动切镜和多语文字渲染结合,使一次生成更接近“可直接上线”的成片。这对短剧、漫剧、广告与社媒内容的生产线是实际降本增效。
行业判断:交付标准正在发生变化
在 Video Arena 的榜单上,Vidu Q3 不仅把时长从 Q2 的 8 秒提升到 16 秒,还首次在主流产品中将“声画同出”作为默认交付形态。更重要的是,它的优势不再依赖某一帧的视觉惊艳,而是以对白、节奏、镜头切换与文字渲染的整体可用性取胜。这意味着国产视频模型已开始从“技术追赶”转向“内容生产力”的竞争:不只是生成一支样片,更是批量生产可直接上线的内容。
结语:以“交付”为核心看 AI 视频
从产品经理的视角,我更看重交付标准而非单点效果。Vidu Q3 的价值在于把“声画同出、镜头自动切换、三语文字渲染”统一到 16 秒的一次生成之中,让生成结果更接近成片。对于专业用户,这意味着工作流可以从“拿到素材再做后期”转向“生成‑轻调‑上线”。我会继续用它制作自己的视频号内容,也会关注其在角色一致性、长时叙事与高分辨率导出上的进一步进展。感兴趣的团队可以直接去官网与开发者平台试用,评估是否适配你的内容生产线。
使用「MACTALK」这个邀请码注册,可以直接获得 500 积分。
体验地址: