作为一名产品经理,在浏览和体验了大量 AI 控制电脑的开源项目后,我发现这个领域正经历从单点工具向完整框架的演进。
这些项目的核心差异不在于"有多强大",而在于采用的技术路线、适配的操作系统、以及解决的具体问题场景各不相同。
我整理了以下 10 个代表性项目,按照技术特征和适用场景分类呈现。
01. Open Interpreter
简介:一个本地代码解释器,让 AI 大模型直接在终端中运行代码并控制电脑。GitHub 星数:61K+
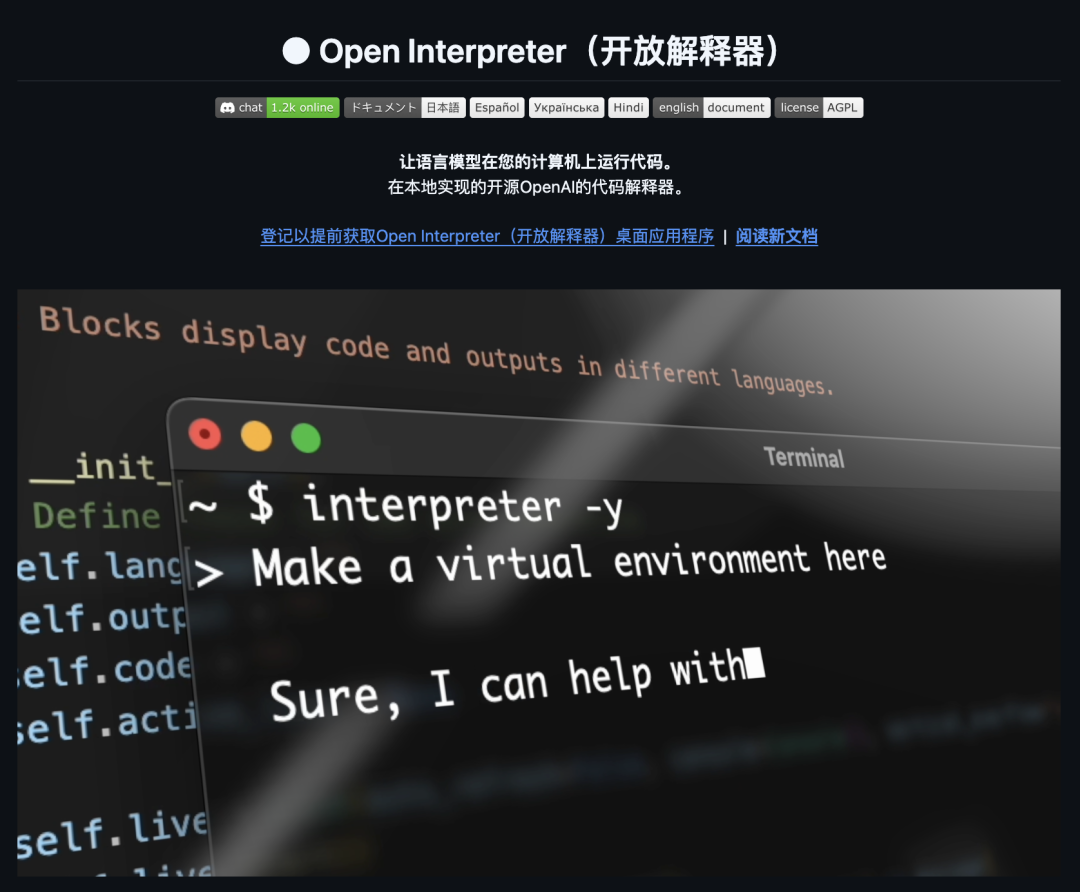
功能特色:
- 支持 Python、JavaScript、Shell 等多种语言的本地执行
- 通过对话界面与模型交互,无需复杂的脚本编写
- 具备网络访问能力,支持自由联网(不限于必应搜索)
- 支持本地文件操作:批量重命名、格式转换、Excel 处理等
- 支持系统级控制:打开应用、发送邮件、修改系统设置
- 兼容本地模型(如 Ollama、Jan),数据不上传云端,隐私可控
- 示例应用场景:系统配置自动化、大型数据表格分析与可视化
02. OmniParser(微软开源)
简介:专门用于屏幕解析的工具,将截图转化为结构化数据,是构建 GUI Agent 的核心视觉组件。V2 版本在 Hugging Face 获得广泛关注。

功能特色:
- Detect 阶段:通过 YOLO 模型精准框选屏幕上的可交互元素(按钮、输入框、图标、侧边栏),对微小图标也能精确识别
- Caption 阶段:使用 Florence-2 或 BLIP-2 模型为每个框选元素生成功能描述(如"搜索图标""设置按钮")
- Grounding 阶段:将坐标和描述传递给 GPT-4V 或 DeepSeek,建立大模型与屏幕元素的映射关系
- 可视为连接大模型与电脑屏幕的高精度感知接口
03. Self-Operating Computer
简介:一个开源框架,使多模态 AI 模型能像人类一样操作计算机。GitHub 星数:10K+
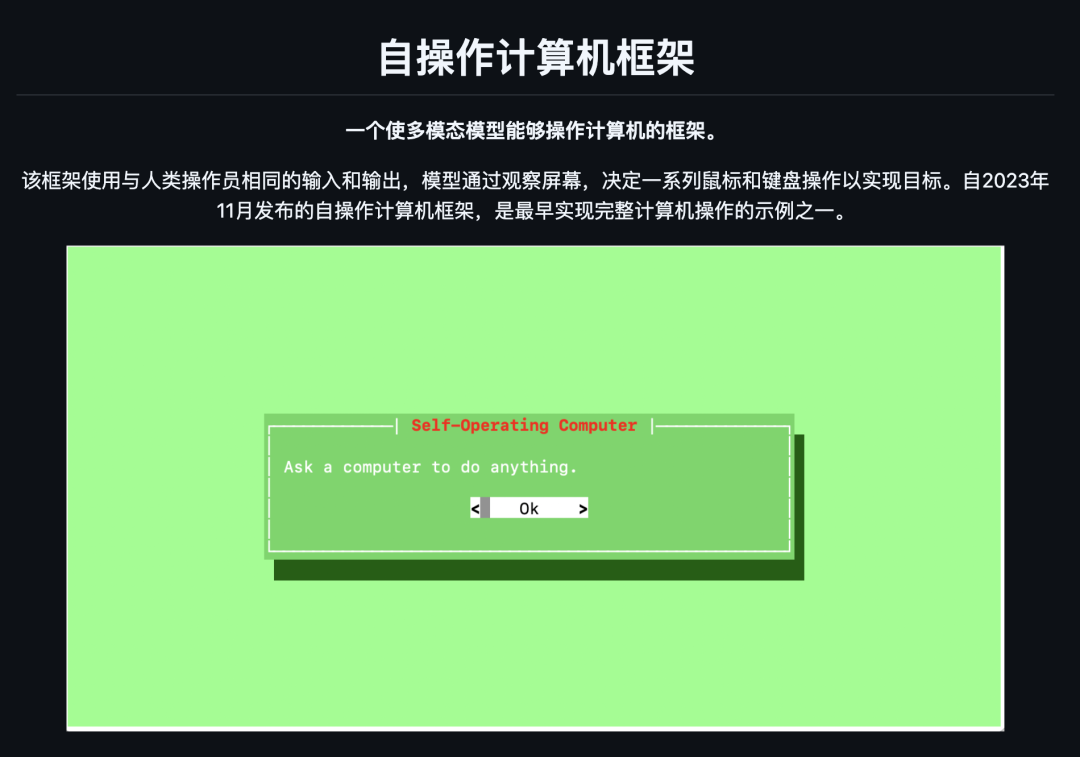
功能特色:
- 通过屏幕截图进行视觉识别,调用系统鼠标和键盘接口(基于 pyautogui 库)
- 跨平台支持:macOS、Windows、Linux
- OCR 模式:为屏幕上的可点击元素生成坐标哈希图,提高点击准确率
- Set-of-Mark (SoM) 提示:在 UI 元素上标记数字标签,模型仅需输出数字即可定位,类似特斯拉自动驾驶的视觉标注方式
- 支持语音输入指令,增加交互便捷性
04. Agent-S
简介:前沿的 GUI 智能体框架,首个在 OSWorld 基准测试上超越人类水平的模型(评分 72.60%)。GitHub 星数:9K+

功能特色:
- 经验增强的层次化规划:不是逐步盲目操作,而是先搜索外部知识(如在线教程)和检索内部记忆,将大任务分解为子任务
- Agent-计算机接口:不直接处理原始像素,而是通过中间层更精确地感知 GUI 元素
- 双重记忆机制:叙事记忆存储高层次任务经验,情景记忆存储具体操作步骤,使用频次越多越擅长处理复杂任务
- 更接近人类认知过程的决策架构
05. UFO(微软开源)
简介:为 Windows 生态深度定制的原生级智能体系统,不仅依赖屏幕视觉,还能调用底层系统接口。
功能特色:
- 结合视觉方案与底层 API:Windows UI Automation、Win32、COM API
- 不仅截图识别,还能直接读取控件树,获知按钮名称、状态、隐藏属性等深层信息
- 点击准确率显著高于纯视觉方案
- 针对 Office 全家桶、文件资源管理器等常用软件优化
- 双代理架构:AppAgent 和 OSAgent 分别处理应用内部逻辑和操作系统级操作
- 支持跨应用复杂流程:如从 PPT 提取内容并发邮件
- 仅支持 Windows 平台
06. Cradle(智源研究院 BAAI 开源)
简介:让 AI 智能体仅通过屏幕截图和标准输入/输出接口操作任何软件和游戏,无需后端 API 或代码访问。

功能特色:
- 应用场景覆盖广:可玩《荒野大镖客》《城市天际线》等游戏,也可操作飞书、Chrome、剪映等专业软件
- 标准化框架设计:
- 感知模块:提取屏幕中的关键信息,识别 UI、图标、文本或 3D 场景
- 决策与规划:根据任务目标和屏幕状态规划下一步行动
- 自我反思:操作失败时分析原因并修正策略
- 记忆系统:短期记忆记录最近操作序列,长期记忆存储成功经验和工具手册(RAG)
- 执行模块:将规划转换为键盘和鼠标指令
07. OS-Copilot
简介:一个构建通用操作系统代理的框架,核心 Agent 为 FRIDAY,强调自我学习和自我改进能力。
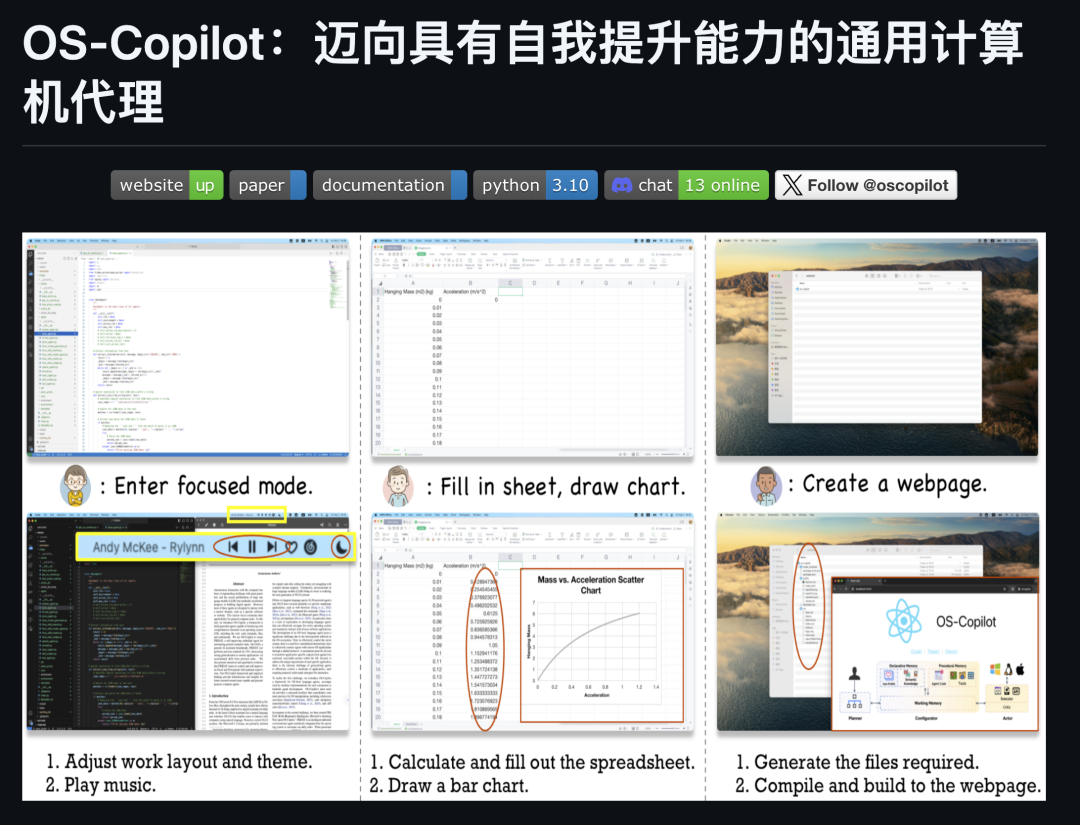
功能特色:
- 能处理从未接触过的应用程序
- 通过自我改进机制学习如何操作 Excel、PPT、网页浏览等常见任务
- 目标是创建无缝集成到操作系统中的个人助理
- 重点在于 Agent 的自我学习能力而非预先优化
08. ShowUI
简介:轻量级端到端视觉-语言-动作(Vision-Language-Action)模型,专为 GUI 智能体设计。
功能特色:
- 解决大模型处理 UI 界面时的高延迟和计算成本问题
- 模型小巧高效,适合本地部署
- 提供低延迟的 UI 自动化控制
- 更快速、更精准的屏幕元素定位和操作
- 适合对性能敏感的场景
09. UI-TARS Desktop(字节跳动开源)
简介:基于 UI-TARS 视觉语言模型的 GUI 智能体桌面应用,支持通过自然语言直接控制计算机。

功能特色:
- 端到端视觉模型架构,无需复杂中间代码解析
- 直接像人类一样看屏幕并操作鼠标键盘
- 开箱即用,降低部署门槛
- 支持远程计算机控制
- 跨平台:Windows 和 macOS
- 代表当前较新的高性能 GUI Agent 实现方向
总体观察
这 9 个项目反映了 AI 控制电脑领域的三条主要技术路线:
1. 纯视觉方案(Self-Operating Computer、ShowUI、UI-TARS Desktop)—— 通过屏幕截图和深度学习模型理解 UI,跨平台通用但需要较强的视觉模型能力。
2. 混合方案(UFO、OmniParser)—— 结合系统级 API 与视觉识别,牺牲通用性换取准确度和性能,多见于特定生态(如 Windows)的优化。
3. 框架与记忆方案(Agent-S、Cradle、OS-Copilot)—— 强调多模块协作、记忆机制和自适应学习,处理更复杂的多步骤任务。
选择哪个项目取决于你的实际需求:
如果追求快速原型和跨平台支持,Open Interpreter 和 Self-Operating Computer 是较好的起点;
如果专注于 Windows 环境的生产级应用,UFO 和 OmniParser 的组合更稳定;
如果需要处理复杂、长序列任务,Agent-S 和 Cradle 的架构设计更完善。
这个领域仍在快速迭代,没有绝对的"最优"选择,只有最匹配场景的方案。