今天苏米就大家了解RAGFlow这个神器,看看它是如何让AI变得更靠谱,让我们的文档管理和知识问答变得更智能的。
什么是RAGFlow?
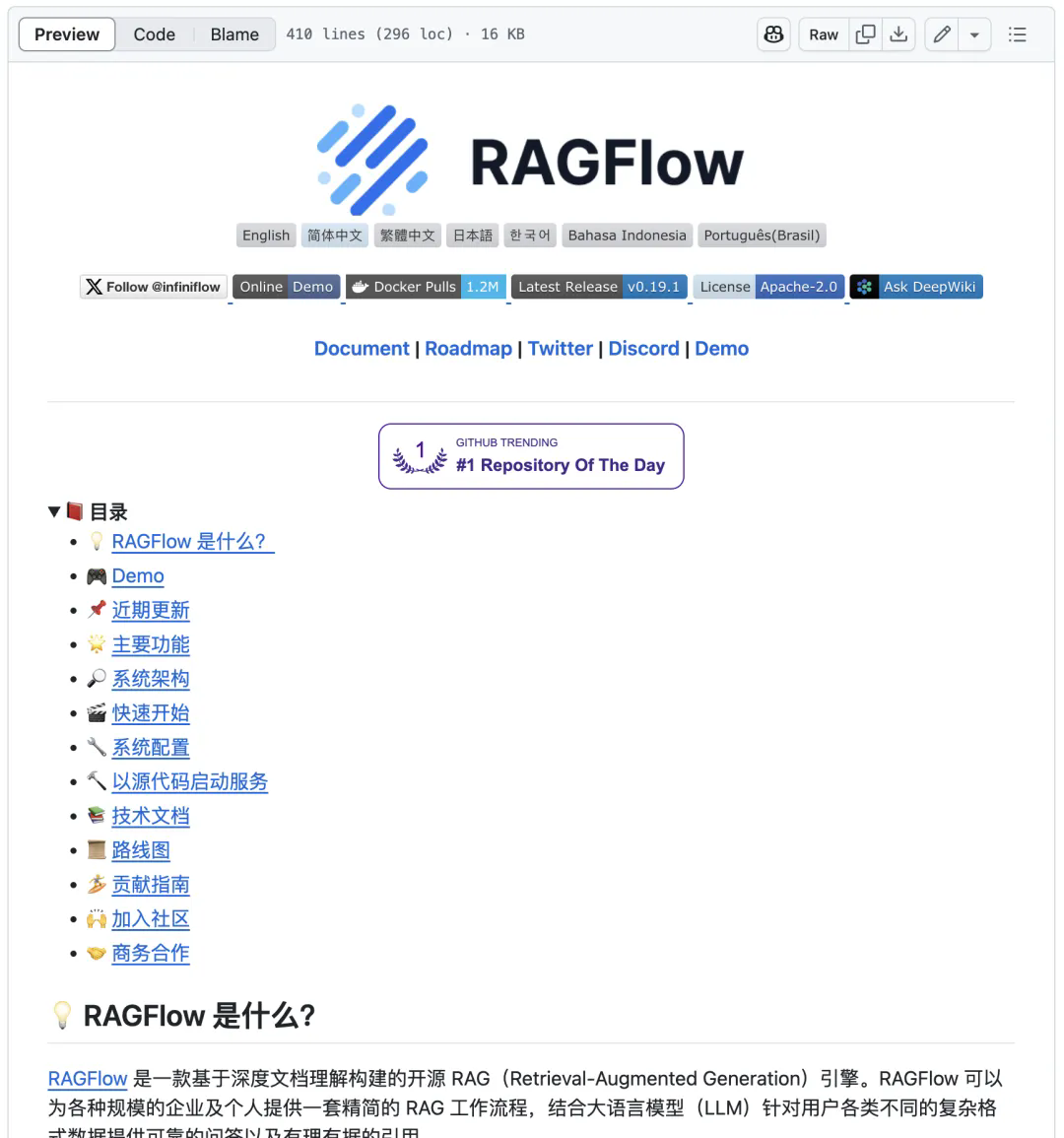
RAGFlow是一个开源的RAG(检索增强生成)引擎,简单来说,它就是让AI在回答问题之前,先去你的知识库里"翻翻书",然后再给出答案。
我在体验过程中发现,RAGFlow最大的亮点就是它能够"有理有据"地回答问题。当我问它某个业务问题时,它不仅会给出准确答案,还会告诉我这个答案是从哪份文档的哪一页找到的。这种"溯源"能力真的让人安心不少,再也不用担心AI在那里信口开河了。
1. 深度理解各种复杂文档
在实际使用中,我发现RAGFlow对文档的理解能力确实很强。无论是Word文档、PPT演示文稿、Excel表格,还是PDF扫描件,甚至是图片和网页,它都能准确识别和提取信息。
特别是对于那些带有复杂表格的财务报告或者扫描版的合同文件,传统的文本提取工具往往会出现格式混乱的问题,但RAGFlow的"深度文档理解"能力让这些问题得到了很好的解决。
更贴心的是,它会把大文档智能切分成更小的"知识块",而且这个过程是可视化的,你还能手动调整切分方式,确保信息的完整性和准确性。
2. 灵活的RAG工作流程
RAGFlow提供了一套近乎"全自动"的工作流程,从个人使用到企业级部署都能轻松搞定。你可以自由选择搭配不同的大语言模型,比如OpenAI的GPT-4o、百度文心一言、火山方舟、DeepSeek等等。
在我的测试中,即使上传了几十个大文件,系统的检索速度依然很快,这得益于它优秀的向量化处理和索引优化。
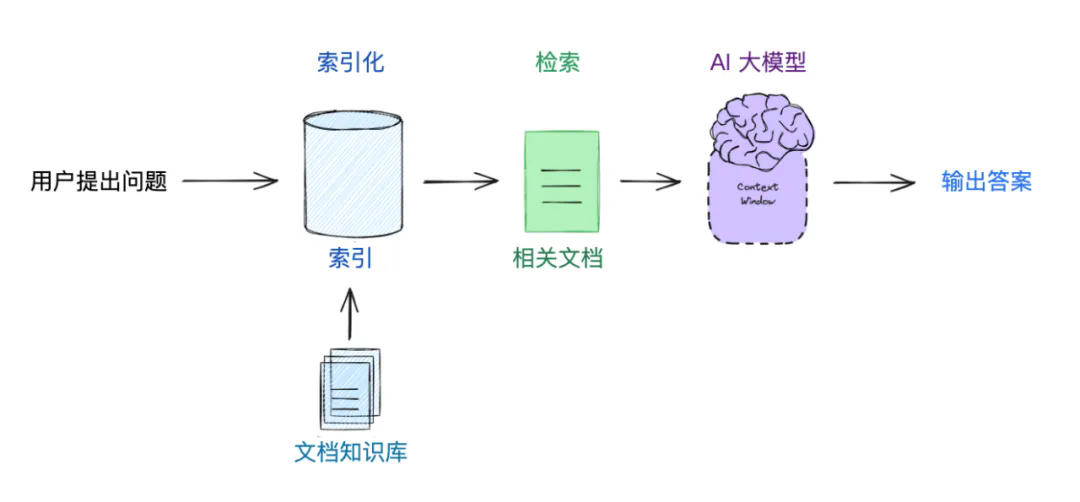
3. 从文档到问答,整个 RAG 工作流长这样
RAGFlow 的核心流程其实并不复杂,甚至可以说是“模块化搭积木”:
-
文档上传:支持各种格式,上传时自动切块;
-
知识入库:内置的向量引擎帮你做高效检索;
-
模型对接:你可以自由接入 OpenAI GPT-4o、文心一言、DeepSeek 等大模型;
-
语义问答:用户提问后,系统从知识库中检索相关内容,再结合大模型生成最终回答。
整个流程可以全自动运行,也允许你手动介入优化,每一环都透明可控。
部署体验
作为一个经常折腾各种AI工具的产品经理,我对RAGFlow的部署过程印象深刻——真的比预想中简单太多了。
硬件要求不算苛刻
-
CPU:至少4核(对于大多数办公电脑来说都够用)
-
内存:至少16GB(现在的主流配置)
-
硬盘:至少50GB(建议预留更多空间存储文档)
-
软件:Docker和Docker Compose(这是关键)
部署步骤实战
整个部署过程我大概花了30分钟,主要时间都在等待镜像下载:
系统准备:首先需要调整一个叫vm.max_map_count的系统参数,确保不小于262144。
获取代码:
git clone https://github.com/infiniflow/ragflow.git
一键启动:进入docker目录,运行:
docker compose -f docker-compose-CN.yml up -d
等待完成:用docker logs命令查看启动状态,看到服务器成功启动的提示就OK了。

首次配置:在浏览器访问你的服务器IP,首次登录后需要配置大模型的API Key。
开始使用:上传你的文档,开始智能问答体验。
整个过程中,我最大的感受就是"傻瓜式"操作,即使是技术小白也能轻松上手。
总结
RAGFlow作为一个开源的RAG引擎,确实解决了我们在日常工作中遇到的很多痛点。它不仅让AI变得更可靠,还大大提升了我们处理文档和获取信息的效率。
对于像我这样经常需要处理大量文档的产品经理来说,RAGFlow已经成为了我的得力助手。如果你也在为文档管理和知识问答而烦恼,不妨试试这个"神器"——相信它会给你带来意想不到的惊喜。
最后提醒一下,虽然RAGFlow很强大,但选择合适的大模型和做好文档预处理同样重要。只有把这些环节都做好,才能发挥出它的最大价值。